Content #
Stevens 的《UNIX 网络编程:套接字联网 API》
 November 5, 2023
November 5, 2023
November 5, 2023
November 5, 2023
iptables -I INPUT -p tcp --dport 80 -j REJECT
sudo tcpdump -i any -w telnet-80-reject.pcap host 47.94.129.219 and port 80
在客户端发起 telnet 服务端 IP 80。
$ telnet 47.94.129.219 80
Trying 47.94.129.219...
telnet: connect to address 47.94.129.219: Connection refused
telnet: Unable to connect to remote host
telnet 立刻退出,奇怪的是,抓包文件里并没有期望的 TCP RST?
sudo tcpdump -i any -w telnet-80-reject.pcap host 47.94.129.219
再来看抓到的报文,很意外,居然对端回复了一个 ICMP 消息:Destination unreachable (Port unreachable)。而且,这个 ICMP 消息不仅通过 type=3 表示,这是一个“端口不可达”的错误消息,而且在它的 payload 里面,还携带了完整的 TCP 握手包的信息。而这个握手包,可是客户端发过来的。
...
November 5, 2023
iptables -I INPUT -p tcp --dport 80 -j DROP
sudo tcpdump -i any -w telnet-80.pcap port 80
telnet 服务端IP 80
这个 telnet 会挂起,大约一两分钟后才会失败退出。原因在于:握手请求一直没成功。客户端一共有 7 个 SYN 包发出,或者说,除了第一次 SYN,后续还有 6 次重试。数据包之间的时间间隔,会是 1 秒,2 秒,4.2 秒,8.2 秒,16.1 秒,33 秒,每个间隔是上一个的两倍左右。到第 6 次重试失败后,客户端就彻底放弃了。
这里的翻倍时间,就是“指数退避”(Exponential backoff)原则的体现。这里的时间不是精确的整秒,因为指数退避原则本身就不建议在精确的整秒做重试,最好是有所浮动,这样可以让重试成功的机会变得更大一些。
TCP 握手没响应的话,操作系统会做重试。在 Linux 中,这个设置是由内核参数 net.ipv4.tcp_syn_retries 控制的,默认值为 6,也就是我们前面刚观察到的现象。以下就是 Ubuntu 20.04 测试机的配置:
$ sudo sysctl net.ipv4.tcp_syn_retries
net.ipv4.tcp_syn_retries = 6
还有另外好几个有关 TCP 重试的设置值,也都可以调整。更全面的内容呢,你可以直接 man tcp,查看 tcp 的内核手册的信息。比如下面就是对于 tcp_syn_retries 的解释:
...
November 4, 2023
November 4, 2023
sudo !!
su -c "!!"
“!” is called event designator, it references a command in your shell history
sudo !w # run the most recent command starts with a given string
!<string>
host www.google.com 8.8.8.8
ping -c1 !^
unzip report.zip
rm !$
!!:N
<event_designator>:<number>
The first word is 0(command), the second word is 1.
...
November 4, 2023
在视频编码中,宏块(Macroblock)是一种基本的编码单元,用于对视频帧进行分割和编码。
宏块是由一组相邻的像素块组成的,通常是一个大小为16x16像素的矩形区域。每个宏块包含的像素块数量取决于视频编码标准,如H.264/AVC或HEVC。
对于每个宏块,编码器对其进行处理并使用各种技术进行预测、变换和压缩。首先,帧内预测(Intra Prediction)技术通过利用同一帧中的相邻像素块进行预测,减少冗余信息。然后,帧间预测(Inter Prediction)技术利用之前已解码的帧进行预测,如前一帧或其他已解码的参考帧,以进一步减少冗余。最后,对预测误差进行变换、量化、熵编码等处理,以便进行压缩和存储。
宏块的引入可以提高视频编码的效率,因为它允许编码器针对每个宏块单独进行处理,从而适应不同的图像内容和运动特性。同时,宏块级别的处理也为视频的各种操作(如剪切、缩放、旋转等)提供了更高的灵活性。
此外,宏块也可以在视频解码时用于快速定位和解码特定的帧区域。由于宏块的大小相对较小,因此在解码时只需要处理少量连续宏块,而不需要解码整个视频帧。这减少了解码的时间和计算量,同时还可以提高解码的效率和质量。
需要注意的是,宏块在不同的视频编码标准中可能有不同的定义和实现方式。例如,对于H.264/AVC和HEVC等现代视频编码标准,宏块的大小通常为16x16像素。对于早期的编码标准,如MPEG-2和MPEG-4,宏块的大小则可能为8x8或其他值。此外,某些视频编码器还可能使用更小的块或更大的块作为编码单元。
November 4, 2023
在视频编码中, B帧(Bi-directional Prediction) P帧(Predicted Picture)是两种重要的帧类型。
P帧是基于前面的已解码帧进行预测编码的帧类型。它利用已解码的参考帧(通常为前一帧或关键帧)来预测当前帧的内容,只编码预测误差。这使得 P帧的压缩效率较高,因为它不需要存储全部像素数据,只存储预测误差信息。P帧可以减少视频文件大小,但解码时需要依赖参考帧的存在。
B帧是双向预测编码的帧类型。它利用已解码的前后两个参考帧进行预测,得到当前帧的预测结果。与P帧不同,B帧可以使用未来帧作为参考,因此它具有更高的压缩效率。B帧可以进一步减小视频文件大小,并且不依赖其他帧来进行解码。
November 4, 2023
存储系统的服务对象有 3 个:
BlockManager 的职责,正是在 Executors 中管理这 3 类数据的存储、读写与收发。就存储介质来说,这 3 类数据所消耗的硬件资源各不相同。
具体来说,Shuffle 中间文件消耗的是节点磁盘,而广播变量主要占用节点的内存空间,RDD Cache 则是“脚踏两条船”,既可以消耗内存,也可以消耗磁盘。
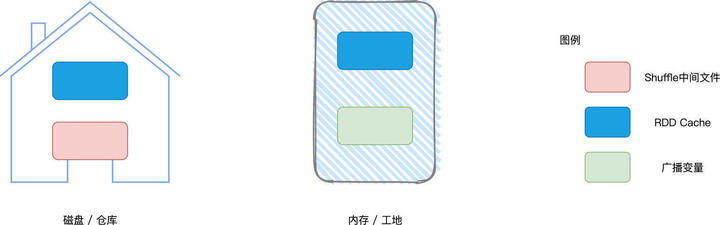
不管是在内存、还是在磁盘,这些数据都是以数据块(Blocks)为粒度进行存取与访问的。数据块的概念与 RDD 数据分区(Partitions)是一致的,在 RDD 的上下文中,说到数据划分的粒度,我们往往把一份数据称作“数据分区”。而在存储系统的上下文中,对于细分的一份数据,我们称之为数据块。
有了数据块的概念,我们就可以进一步细化 BlockManager 的职责。 BlockManager 的核心职责,在于管理数据块的元数据(Meta data),这些元数据记录并维护数据块的地址、位置、尺寸以及状态。为了让你直观地感受一下元数据,我把它的样例放到了下面的示意图里,你可以看一看。

只有借助元数据,BlockManager 才有可能高效地完成数据的存与取、收与发。
November 4, 2023
所谓定向计数,它指的是只对某些单词进行计数,例如,给定单词列表 list,我们只对文件 wikiOfSpark.txt 当中的“Apache”和“Spark”这两个单词做计数,其他单词我们可以忽略。
import org.apache.spark.rdd.RDD
val rootPath: String = _
val file: String = s"${rootPath}/wikiOfSpark.txt"
// 读取文件内容
val lineRDD: RDD[String] = spark.sparkContext.textFile(file)
// 以行为单位做分词
val wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" "))
// 创建单词列表list
val list: List[String] = List("Apache", "Spark")
// 使用list列表对RDD进行过滤
val cleanWordRDD: RDD[String] = wordRDD.filter(word => list.contains(word))
// 把RDD元素转换为(Key,Value)的形式
val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, 1))
// 按照单词做分组计数
val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)
// 获取计算结果
wordCounts.collect
// Array[(String, Int)] = Array((Apache,34), (Spark,63))
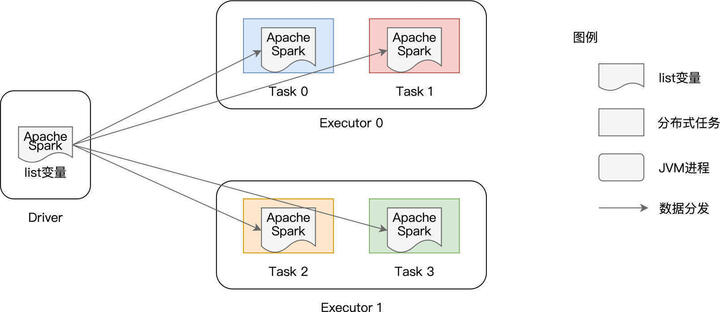
如上图所示,list 变量本身是在 Driver 端创建的,它并不是分布式数据集(如 lineRDD、wordRDD)的一部分。因此,在分布式计算的过程中,Spark 需要把 list 变量分发给每一个分布式任务(Task),从而对不同数据分区的内容进行过滤。
在这种工作机制下,如果 RDD 并行度较高、或是变量的尺寸较大,那么重复的内容分发就会引入大量的网络开销与存储开销,而这些开销会大幅削弱作业的执行性能。为什么这么说呢?
...
November 4, 2023
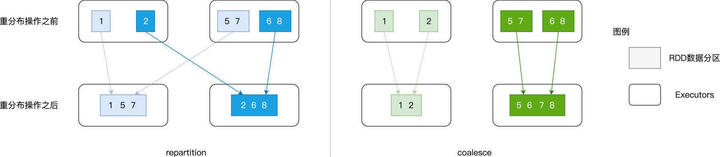
所谓并行度,它实际上就是 RDD 的数据分区数量。RDD 的 partitions 属性,记录正是 RDD 的所有数据分区。因此,RDD 的并行度与其 partitions 属性相一致。开发者可以使用 repartition 算子随意调整(提升或降低)RDD 的并行度,而 coalesce 算子则只能用于降低 RDD 并行度。
为什么 repartition 会引入 Shuffle,而 coalesce 不会呢?原因在于,二者的工作原理有着本质的不同。
给定 RDD,如果用 repartition 来调整其并行度,不论增加还是降低,对于 RDD 中的每一条数据记录,repartition 对它们的影响都是无差别的数据分发。
具体来说,给定任意一条数据记录,repartition 的计算过程都是先哈希、再取模,得到的结果便是该条数据的目标分区索引。对于绝大多数的数据记录,目标分区往往坐落在另一个 Executor、甚至是另一个节点之上,因此 Shuffle 自然也就不可避免。
coalesce 则不然,在降低并行度的计算中,它采取的思路是把同一个 Executor 内的不同数据分区进行合并,如此一来,数据并不需要跨 Executors、跨节点进行分发,因而自然不会引入 Shuffle。