Content #
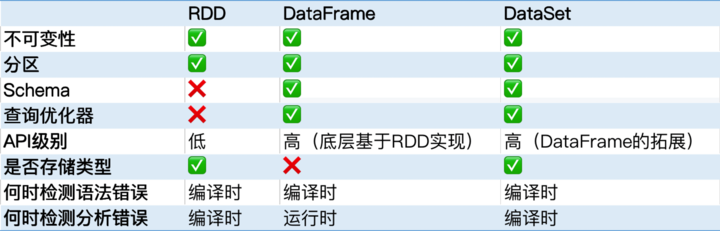
RDD 表示已被分区、不可变的,并能够被并行操作的数据集合。
- 分区的
- 不可变的
- 分区信息不可以被改变
- 只能转换(Transformation)现有的 RDD
- 依赖关系(RDD)
- 能被并行操作的由于单个 RDD 的分区特性,使得它天然支持并行操作,即不同节点上的数据可以被分别处理,然后产生一个新的 RDD。
 November 8, 2023
November 8, 2023
November 8, 2023
November 8, 2023
withColumnRenamed 是重命名现有的数据列,而 withColumn 则用于生成新的数据列。
如果打算把 employeesDF 当中的“gender”重命名为“sex”,就可以用 withColumnRenamed 来帮忙:
employeesDF.withColumnRenamed(“gender”, “sex”)。
withColumn 也可以充分利用 Spark SQL 提供的 Built-in Functions 来灵活地生成数据。
比如,基于年龄列,我们想生成一列脱敏数据,隐去真实年龄,你就可以这样操作。
scala> employeesDF.withColumn("crypto", hash($"age")).show
+---+-------+---+------+-----------+
| id| name|age|gender| crypto|
+---+-------+---+------+-----------+
| 1| John| 26| Male|-1223696181|
| 2| Lily| 28|Female|-1721654386|
| 3|Raymond| 30| Male| 1796998381|
+---+-------+---+------+-----------+
我们使用内置函数 hash,生成一列名为“crypto”的新数据,数据值是对应年龄的哈希值。
16 | 数据转换:如何在DataFrame之上做数据处理?
November 8, 2023
如果数据流中的每个词语都有一个时间戳代表词语产生的时间,那么要怎样实现,每隔 10 秒钟输出过去 60 秒内产生的前十热点词呢?
#这个DataFrame代表词语的数据流,schema是 { timestamp: Timestamp, word: String}
words = ...
windowedCounts = words.groupBy(
window(words.timestamp, "1 minute", "10 seconds"),
words.word
).count()
.sort(desc("count"))
.limit(10)
基于词语的生成时间,我们创建了一个窗口长度为 1 分钟,滑动间隔为 10 秒的 window。然后,把输入的词语表根据 window 和词语本身聚合起来,并统计每个 window 内每个词语的数量。之后,再根据词语的数量进行排序,只返回前 10 的词语。
17 | Structured Streaming:如何用DataFrame API进行实时数据分析?
November 8, 2023
Spark Streaming 提供的 DStream API 与 RDD API 很类似,相对比较低 level。
当我们编写 Spark Streaming 程序的时候,本质上就是要去构造 RDD 的 DAG 执行图,然后通过 Spark Engine 运行。这样开发者身上的担子就很重,很多时候要自己想办法去提高程序的处理效率。
Structured Streaming 提供的 DataFrame API 就是这么一个相对高 level 的 API,大部分开发者都很熟悉关系型数据库和 SQL。这样的数据抽象可以让他们用一套统一的方案去处理批处理和流处理,不用去关心具体的执行细节。
而且,DataFrame API 是在 Spark SQL 的引擎上执行的,Spark SQL 有非常多的优化功能,比如执行计划优化和内存管理等,所以 Structured Streaming 的应用程序性能很好。
Spark Streaming 是准实时的,它能做到的最小延迟在一秒左右。
虽然 Structured Streaming 用的也是类似的微批处理思想,每过一个时间间隔就去拿来最新的数据加入到输入数据表中并更新结果,但是相比起 Spark Streaming 来说,它更像是实时处理,能做到用更小的时间间隔,最小延迟在 100 毫秒左右。
而且在 Spark 2.3 版本中,Structured Streaming 引入了连续处理的模式,可以做到真正的毫秒级延迟,这无疑大大拓展了 Structured Streaming 的应用广度。
...
November 8, 2023
事件时间(Event Time)和处理时间(Processing Time)
在处理大规模数据的时候,我们通常还会关心时域(Time Domain)的问题。
事件时间指的是一个数据实际产生的时间点,而处理时间指的是处理数据的系统架构实际接收到这个数据的时间点。
下面我来用一个实际的例子进一步说明这两个时间概念。
现在假设,你正在去往地下停车场的路上,并且打算用手机点一份外卖。选好了外卖后,你就用在线支付功能付款了,这个时候是 12 点 05 分。恰好这时,你走进了地下停车库,而这里并没有手机信号。因此外卖的在线支付并没有立刻成功,而支付系统一直在重试(Retry)“支付”这个操作。
当你找到自己的车并且开出地下停车场的时候,已经是 12 点 15 分了。这个时候手机重新有了信号,手机上的支付数据成功发到了外卖在线支付系统,支付完成。
在上面这个场景中你可以看到,支付数据的事件时间是 12 点 05 分,而支付数据的处理时间是 12 点 15 分。
November 6, 2023
November 6, 2023
November 5, 2023
握手阶段 RST 的序列号是 1,确认号也是 1。Wireshark过滤条件可以这么写:
tcp.seq eq 1 and tcp.ack eq 1
要展示连接建立后的RST包,就要排除握手阶段中的RST包,过滤条件可写成:
ip.addr eq 10.255.252.31 and tcp.flags.reset eq 1 and !(tcp.seq eq 1 and tcp.ack eq 1)
04 | 挥手:Nginx日志报connection reset by peer是怎么回事?
November 5, 2023
搜索技巧:使用 frame.time 过滤器。比如下面这样:
frame.time >="dec 01, 2015 15:49:48" and frame.time <="dec 01, 2015 15:49:49"
这就可以帮助我们定位到 Nginx 日志中,第一条日志的时间匹配的报文了。
2015/12/01 15:49:48 [info] 20521#0: *55077498 recv() failed (104: Connection reset by peer) while sending to client, client: 10.255.252.31, server: manager.example.com, request: "POST /WebPageAlipay/weixin/notify_url.htm HTTP/1.1", upstream: "http:/10.4.36.207:8080/WebPageAlipay/weixin/notify_url.htm", host: "manager.example.com"
04 | 挥手:Nginx日志报connection reset by peer是怎么回事?
November 5, 2023