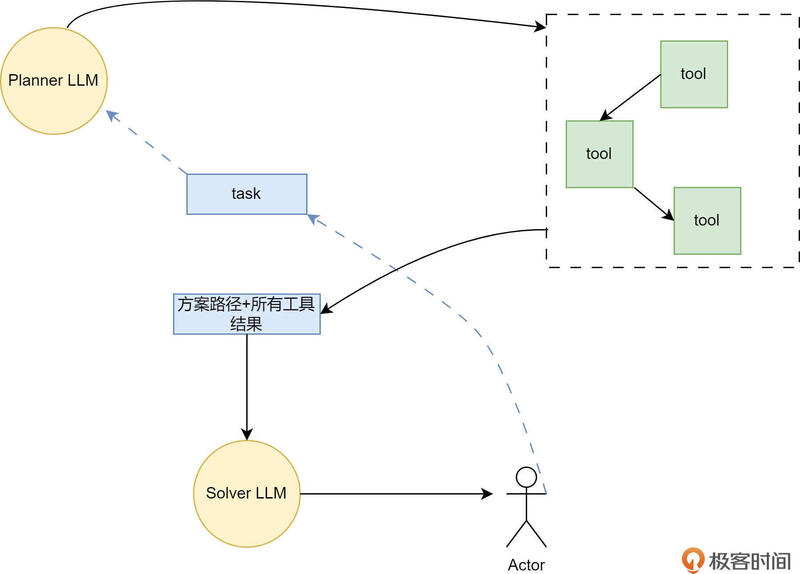
论文《ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models》提出了 ReWOO 思想,即如果大模型能一次性的把所有步骤都告诉人类,人类把每个步骤对应的工具调用结果一次性返回给大模型,不就可以只提问一次就解决问题了吗?
在最开始,我们输入给大模型一个任务,例如,任务为“请问济南的天气如何?”,同时将天气的 API 工具也输入给大模型。此时大模型会进行推理,得出的结论是需要调用天气预报工具来解决问题。
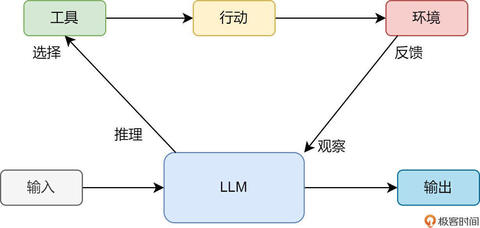
结合第一节课 Function Calling 相关的知识,我们知道,大模型只能选择工具,工具的执行者是人类。于是人类便开始行动,替大模型执行天气工具,并将得到的结果反馈给大模型。
此时重点来了,大模型会观察人类返回的结果,看看结果是否能满足要求。这里的观察主要是观察工具调用的结果对不对,是否有错误。当然这里指的有错误,是工具调用错误,而不是数据错误,例如工具反馈给大模型,济南的温度是 80℃,大模型是不会认为有问题的。但如果反馈给大模型的是“400 bad request”,则大模型就会认为工具调用出问题了,它会重新推理后,再次尝试调用工具。
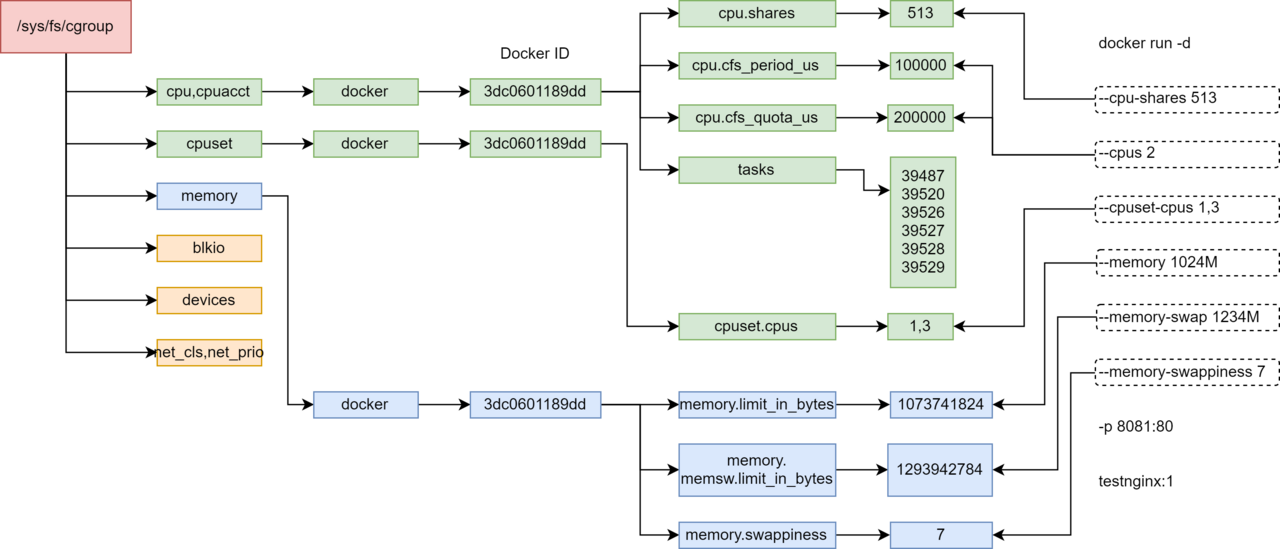
docker run -d --cpu-shares 513 --cpus 2 --cpuset-cpus 1,3 --memory 1024M --memory-swap 1234M --memory-swappiness 7 -p 8081:80 testnginx:1
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3dc0601189dd testnginx:1 "/bin/sh -c 'nginx -…" About a minute ago Up About a minute 0.0.0.0:8081->80/tcp boring_cohen