Content #
路由协议中的管理距离(Administrative Distance,简称AD)是一种对路由选择信息的可信度进行排序的方法。每一种路由协议按可靠性从高到低,依次分配一个信任等级,这个信任等级就是管理距离。正常情况下,管理距离越小,它的优先级就越高,即可信度越高。
对于两种不同的路由协议到一个目的地的路由信息,路由器首先根据管理距离决定相信哪一个协议。例如,直连的AD=0,static静态的AD=1,EIGRP的AD=90, IGRP的AD=100,OSPF的AD=110,RIP的AD=120。这意味着,当路由器面对多种路由协议的信息时,会优先考虑管理距离小的协议。
此外,管理距离的值是一个从0到255的整数值,0是最可信赖的,而255则意味着不会有业务量通过这个路由。值得注意的是,尽管管理距离可以配置为1~9,但它们被保留内部使用,并不推荐使用。
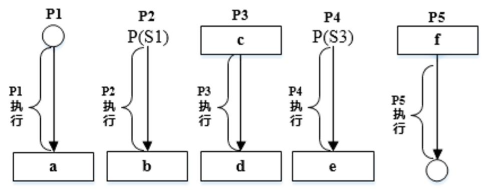
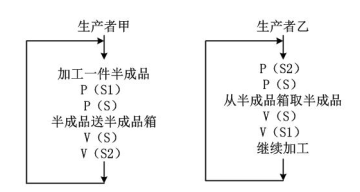
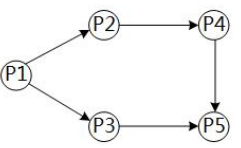 若用PV操作控制进程P1、P2、P3、P4和P5并发执行的过程,则需要设置5个信号
S1、S2、S3、S4和S5,且信号量S1~S5的初值都等于零。
若用PV操作控制进程P1、P2、P3、P4和P5并发执行的过程,则需要设置5个信号
S1、S2、S3、S4和S5,且信号量S1~S5的初值都等于零。