Content #
Emacs中的任何命令都是解析执行表达式的副作用。Sexp的第一个元素是函数。
self-insert-command用于插入字符,与多个字符绑定在一起,这种交互式的函数(interactive function)又称为命令(command)。
Viewpoint #
这意味着Emacs中的每次按键都可以找到对应的函数。
From #
An Introduction to Programming in Emacs Lisp
 June 4, 2022
June 4, 2022
Emacs中的任何命令都是解析执行表达式的副作用。Sexp的第一个元素是函数。
self-insert-command用于插入字符,与多个字符绑定在一起,这种交互式的函数(interactive function)又称为命令(command)。
这意味着Emacs中的每次按键都可以找到对应的函数。
An Introduction to Programming in Emacs Lisp
June 4, 2022
June 3, 2022
关于存储强度与提取强度,我们究竟该用哪一种?或者是以哪一种为主?如果直接抛弃通过重复来记忆的“存储强度”,只依赖于通过建立联系来记忆的“提取强度”,相信很多人会压根就不知道自己记过某些笔记,又如何能将它们与新笔记建立联系呢?
以译者的经验,如果已经是某个领域的资深专家,可以完全依赖“提取强度”去记忆,因为可供建立联系的已有知识已经相当充足了;如果是一个彻头彻尾的新手,还是要以“存储强度”的一遍遍重复作为主要的记忆方式,也是为后续学习储备前置知识;如果是介于新手和专家之间的水平,那么可以将两种方式适当配比,融入自己的学习之中。
已经熟悉这个领域的知识,对新知识要以练提取为主。对于完全陌生的领域,要以训练存储为主。
《卡片笔记写作法:如何实现从阅读到写作》 申克·阿伦斯
June 3, 2022
比约克率先区分了记忆竞争的两种不同类型:存储强度(storage strength)与提取强度(retrieval strength)。以前,人们习惯性地认为,记得越快,学习效果越好。简言之,存储越容易,提取就越快。但他的实验发现了与常识相反的结论:“存储与提取负相关”,也就是说,存入记忆越容易,提取出来越困难;反之,如果你有些吃力地存入,知识提取会更方便。
比如,我们的常识是应该在课堂上记笔记。但是必要难度原理建议,别在课堂上记笔记,边听老师讲课边记笔记,你会听得太明白,写入太容易,但大脑这块硬盘未来会不易提取出来。过些日子,多数内容会被遗忘。反之,如果我们略微增加写入难度,比如晚上回到宿舍或者第二天再写笔记,这样未来提取会更容易。即你有些困难地存入,会记得更好并真正学会。
训练“提取强度”,可采用Zettelkasten等工具,通过建立频繁的联系来增强记忆;训练“存储强度”,可通过闪卡类工具,如Anki软件,通过间隔复习来增强记忆。只有先记住,让原理在头脑中保持住,才有下一步在实践中复现的可能性。
光是练存储强度,只是积累了很了熟悉的素材。光是练提取强度,素材有头脑中保持的时间会不够。只有结合两者,才是好的学习方法。
《卡片笔记写作法:如何实现从阅读到写作》 申克·阿伦斯
June 3, 2022
卢曼笔记主要分哪四类?
《卡片笔记写作法:如何实现从阅读到写作》 申克·阿伦斯
June 1, 2022
June 1, 2022
May 31, 2022
GRUB的分区模块是如何识别分区的?Linux命令下查看到的分区号如何转换成 GRUB能够识别的分区号?
下面来看看我们 Hello OS 的启动项:
menuentry 'HelloOS' {
insmod part_msdos #GRUB加载分区模块识别分区
insmod ext2 #GRUB加载ext文件系统模块识别ext文件系统
set root='hd0,msdos4' #注意boot目录挂载的分区,这是我机器上的情况
multiboot2 /boot/HelloOS.bin #GRUB以multiboot2协议加载HelloOS.bin
boot #GRUB启动HelloOS.bin
}
如果你不知道你的 boot 目录挂载的分区,可以在 Linux 系统的终端下输入命令:df /boot/,就会得到如下结果:
文件系统 1K-块 已用 可用 已用% 挂载点
/dev/sda4 48752308 8087584 38158536 18% /
其中的“sda4”就是硬盘的第四个分区(硬件分区选择 MBR),但是 GRUB 的 menuentry 中不能写 sda4,而是要写“hd0,msdos4”,这是 GRUB 的命名方式, hd0 表示第一块硬盘,结合起来就是第一块硬盘的第四个分区。
May 31, 2022
我们再来看一个列表的例子:
l1 = [1, 2, 3]
l2 = l1
l1.append(4)
l1
[1, 2, 3, 4]
l2
[1, 2, 3, 4]
请问上面的操作中,变量与对象之间的内存结构有何变化?
同样的,我们首先让列表 l1 和 l2 同时指向了[1, 2, 3]这个对象。
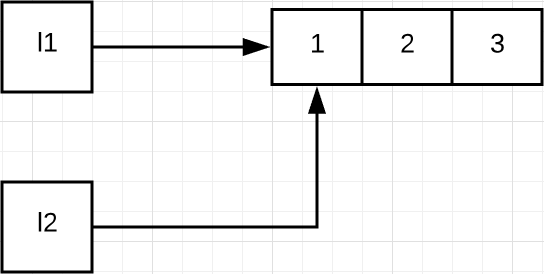 由于列表是可变的,所以 l1.append(4) 不会创建新的列表,只是在原列表的末尾插入了元素 4,变成[1, 2, 3, 4]。由于 l1 和 l2 同时指向这个列表,所以列表的变化会同时反映在 l1 和 l2 这两个变量上,那么,l1 和 l2 的值就同时变为了[1, 2, 3, 4]。
由于列表是可变的,所以 l1.append(4) 不会创建新的列表,只是在原列表的末尾插入了元素 4,变成[1, 2, 3, 4]。由于 l1 和 l2 同时指向这个列表,所以列表的变化会同时反映在 l1 和 l2 这两个变量上,那么,l1 和 l2 的值就同时变为了[1, 2, 3, 4]。
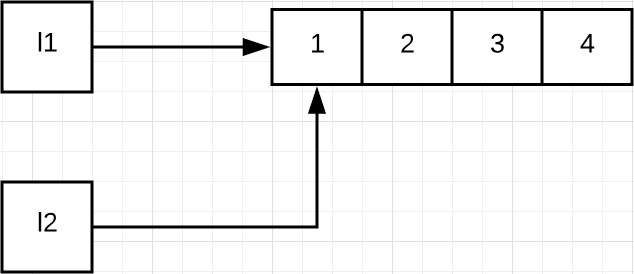 另外,需要注意的是,Python 里的变量可以被删除,但是对象无法被删除。比如下面的代码:
另外,需要注意的是,Python 里的变量可以被删除,但是对象无法被删除。比如下面的代码:
l = [1, 2, 3]
del l
del l 删除了 l 这个变量,从此以后你无法访问 l,但是对象[1, 2, 3]仍然存在。Python 程序运行时,其自带的垃圾回收系统会跟踪每个对象的引用。如果 [1, 2, 3]除了 l 外,还在其他地方被引用,那就不会被回收,反之则会被回收。
16 | 值传递,引用传递or其他,Python里参数是如何传递的?
...
May 31, 2022
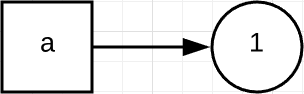
下面的 Python 代码示例:
a = 1
b = a
a = a + 1
这段代码对应的变量与对象之间的内存结构是怎样的?
这里首先将 1 赋值于 a,即 a 指向了 1 这个对象,如下面的流程图所示:
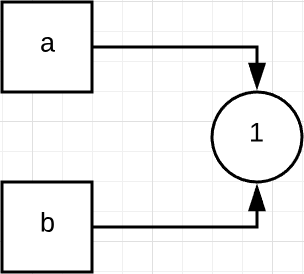
 接着 b = a 则表示,让变量 b 也同时指向 1 这个对象。这里要注意,Python 里的对象可以被多个变量所指向或引用。
接着 b = a 则表示,让变量 b 也同时指向 1 这个对象。这里要注意,Python 里的对象可以被多个变量所指向或引用。
 最后执行 a = a + 1。需要注意的是,Python 的数据类型,例如整型(int)、字符串(string)等等,是不可变的。所以,a = a + 1,并不是让 a 的值增加 1,而是表示重新创建了一个新的值为 2 的对象,并让 a 指向它。但是 b 仍然不变,仍然指向 1 这个对象。因此,最后的结果是,a 的值变成了 2,而 b 的值不变仍然是 1。
最后执行 a = a + 1。需要注意的是,Python 的数据类型,例如整型(int)、字符串(string)等等,是不可变的。所以,a = a + 1,并不是让 a 的值增加 1,而是表示重新创建了一个新的值为 2 的对象,并让 a 指向它。但是 b 仍然不变,仍然指向 1 这个对象。因此,最后的结果是,a 的值变成了 2,而 b 的值不变仍然是 1。
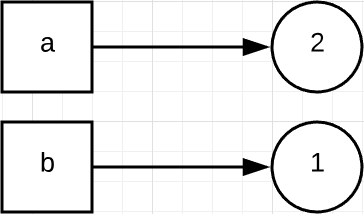 通过这个例子你可以看到,这里的 a 和 b,开始只是两个指向同一个对象的变量而已,或者你也可以把它们想象成同一个对象的两个名字。简单的赋值 b = a,并不表示重新创建了新对象,只是让同一个对象被多个变量指向或引用。同时,指向同一个对象,也并不意味着两个变量就被绑定到了一起。如果你给其中一个变量重新赋值,并不会影响其他变量的值。
通过这个例子你可以看到,这里的 a 和 b,开始只是两个指向同一个对象的变量而已,或者你也可以把它们想象成同一个对象的两个名字。简单的赋值 b = a,并不表示重新创建了新对象,只是让同一个对象被多个变量指向或引用。同时,指向同一个对象,也并不意味着两个变量就被绑定到了一起。如果你给其中一个变量重新赋值,并不会影响其他变量的值。
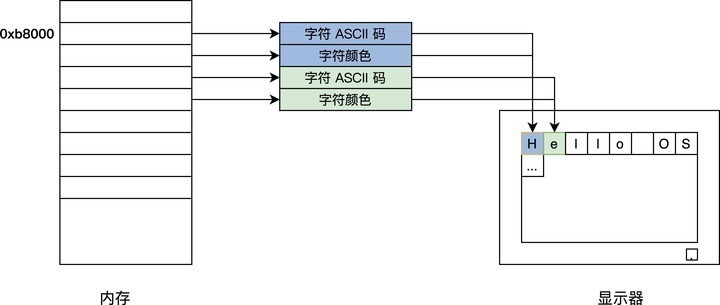 明白了显卡的字符模式的工作细节,下面我们开始写代码。
明白了显卡的字符模式的工作细节,下面我们开始写代码。