中断发生时,CPU 根据需要跳转的特权级,去一个特定的结构中(不同的 CPU
会有所不同,比如 i386 就存在 TSS 中,但不管是什么 CPU,一定会有一个类似的结构),取得目标特权级所对应的 stack 段选择子和栈顶指针,并分别送入 ss 寄存器和 rsp 寄存器,这就完成了一次栈的切换。
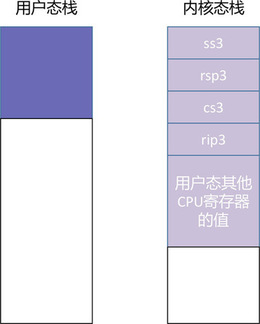
然后,IP 寄存器跳入中断服务程序开始执行,中断服务程序会把当前 CPU 中的所有寄存器,也就是程序的上下文都保存到栈上,这就意味着用户态的 CPU 状态其实是由中断服务程序在系统栈上进行维护的。如图所示:
一般来说,当程序因为 call 指令或者 int 指令进行跳转的时候,只需要把下一条指令的地址放到栈上,供被调用者执行 ret 指令使用,这样可以便于返回到调用函数中继续执行。但上图中的内核态栈里有一点特殊之处,就是 CPU 自动地将用户态栈的段选择子 ss3,和栈顶指针 rsp3 都放到内核态栈里了。这里的数字 3 代表了 CPU 特权级,内核态是 0,用户态是 3。
当中断结束时,中断服务程序会从内核栈里将 CPU 寄存器的值全部恢复,最后再执行"iret"指令(注意不是 ret,而是 iret,这表示是从中断服务程序中返回)。而 iret 指令就会将 ss3/rsp3 都弹出栈,并且将这个值分别送到 ss 和
rsp 寄存器中。这样就完成了从内核栈到用户栈的一次切换。同时,内核栈的
ss0 和 rsp0 也会被保存到前文所说的一个特定的结构中,以供下次切换时使用。