线性回归的正则化
#
正则化(regularization)是用于抑制过拟合的方法的统称,它通过动态调整估计参数的取值来降低模型的复杂度,以偏差的增加为代价来换取方差的下降。这是因为当一些参数足够小时,它们对应的属性对输出结果的贡献就会微乎其微,这在实质上去除了非相关属性的影响。
在线性回归里,最常见的正则化方式就是在损失函数(loss function)中添加正则化项(regularizer),而添加的正则化项 R(λ) 往往是待估计参数的 p-
范数。将均方误差和参数的范数之和作为一个整体来进行约束优化,相当于额外添加了一重关于参数的限制条件,避免大量参数同时出现较大的取值。由于正则化的作用通常是让参数估计值的幅度下降,因此在统计学中它也被称为系数收缩方法(shrinkage method)。
将正则化项应用在基于最小二乘法的线性回归中,就可以得到线性回归的不同修正(penalized linear regression)。添加正则化项之后的损失函数可以写成拉格朗日乘子的形式
\[\hat{E}(w)=\frac{1}{2}\sum_{n=1}^{N} \left[f(x_n,w) - y_n
\right]^2 + \lambda g\left(\parallel w \parallel_p\right)\]
其中,\(g\left(\parallel w \parallel_p\right) < t\)。
其中的 λ 是用来平衡均方误差和参数约束的超参数。当正则化项为 1- 范数时,修正结果就是 LASSO;当正则化项为 2- 范数的平方时,修正结果就是岭回归;当正则化项是 1- 范数和 2- 范数平方的线性组合 α∣∣w∣∣22+(1−α)∣∣w∣∣1 时,修正结果就是弹性网络(elastic net)。
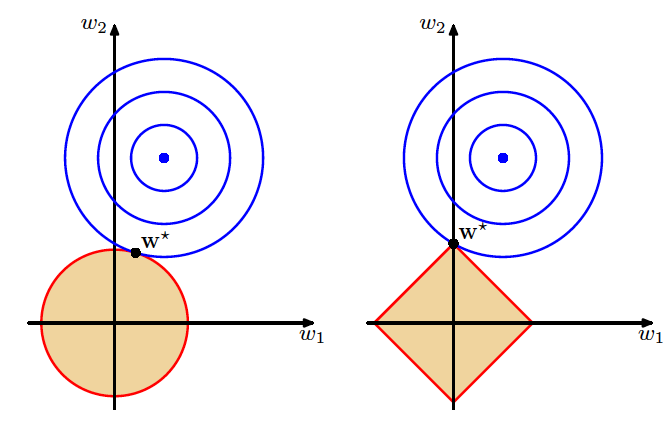 正则化对线性回归的改进(图片来自 Pattern Recognition and Machine
Learning,图 3.4)
正则化对线性回归的改进(图片来自 Pattern Recognition and Machine
Learning,图 3.4)
岭回归和 LASSO 具有不同的几何意义。上图给出的是岭回归(左)和
LASSO(右)的可视化表示。图中的蓝色点表示普通最小二乘法计算出的最优参数,外面的每个蓝色圆圈都是损失函数的等值线,每个圆圈上的误差都是相等的,从里到外误差则越来越大。
红色边界表示的则是正则化项对参数可能取值的约束,这里假定了未知参数的数目是两个。岭回归中要求两个参数的平方和小于某个固定的取值,即 \(w_1^2 +
w_2^2 < t\)。因此解空间就是浅色区域代表的圆形;而 LASSO 要求两个参数的绝对值之和小于某个固定的取值,即 ∣w1∣+∣w2∣<t,因此解空间就是浅色区域代表的方形。
不管采用哪种正则化方式,最优解都只能出现在浅色区域所代表的约束条件下,因而误差等值线和红色边界的第一个交点就是正则化处理后的最优参数。交点出现的位置取决于边界的形状,圆形的岭回归边界是平滑的曲线,误差等值线可能在任何位置和边界相切。
相形之下,方形的 LASSO 边界是有棱有角的直线,因此切点最可能出现在方形的顶点上,这就意味着某个参数的取值被衰减为 0。
...

