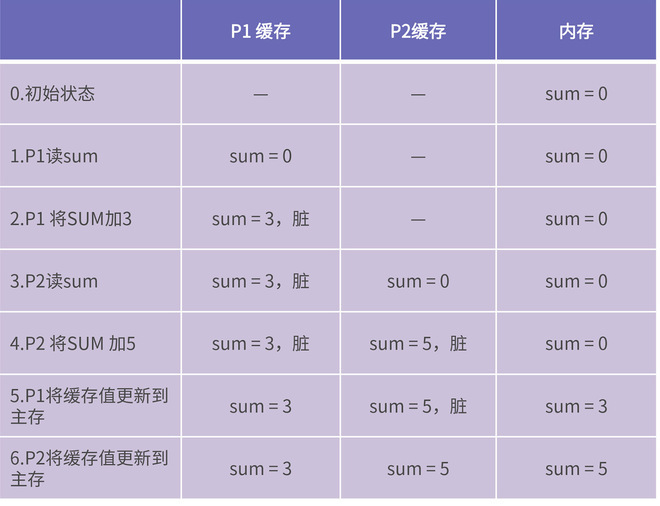
Go Module 的语义导入版本机制 #
我们看到 go.mod 的 require 段中依赖的版本号,都符合 vX.Y.Z 的格式。在 Go Module 构建模式下,一个符合 Go Module 要求的版本号,由前缀 v 和一个满足语义版本规范的版本号组成。
语义版本号分成 3 部分:主版本号 (major)、次版本号 (minor) 和补丁版本号 (patch)。
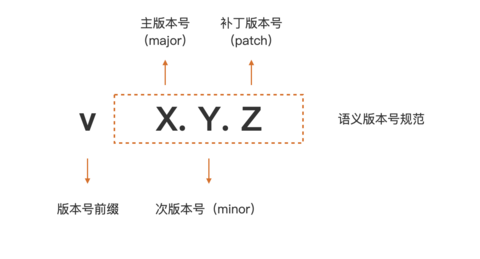
按照语义版本规范,主版本号不同的两个版本是相互不兼容的。而且,在主版本号相同的情况下,次版本号大都是向后兼容次版本号小的版本。补丁版本号也不影响兼容性。
而且,Go Module 规定:如果同一个包的新旧版本是兼容的,那么它们的包导入路径应该是相同的。怎么理解呢?我们来举个简单示例。我们就以 logrus 为例,它有很多发布版本,我们从中选出两个版本 v1.7.0 和 v1.8.1.。按照上面的语义版本规则,这两个版本的主版本号相同,新版本 v1.8.1 是兼容老版本 v1.7.0 的。那么,我们就可以知道,如果一个项目依赖 logrus,无论它使用的是 v1.7.0 版本还是 v1.8.1 版本,它都可以使用下面的包导入语句导入 logrus 包:
import "github.com/sirupsen/logrus"
那么问题又来了,假如在未来的某一天,logrus 的作者发布了 logrus v2.0.0 版本。那么根据语义版本规则,该版本的主版本号为 2,已经与 v1.7.0、 v1.8.1 的主版本号不同了,那么 v2.0.0 与 v1.7.0、v1.8.1 就是不兼容的包版本。然后我们再按照 Go Module 的规定,如果一个项目依赖 logrus v2.0.0 版本,那么它的包导入路径就不能再与上面的导入方式相同了。那我们应该使用什么方式导入 logrus v2.0.0 版本呢?
...