gdb的display与print命令有何区别? #
display [expr]命令执行过后,接下来的每次程序停下来时,[expr]的内容都会自动展示出来。
print命令只是打印当前状态下的表达式内容。
 July 21, 2022
July 21, 2022
July 21, 2022
July 21, 2022
TUI模式: Ctrl+x a 确认原则 让gdb暂停程序执行的三种方式 gdb显示的是将要执行的行 重复执行上一个命令 源代码行的错觉
display与print命令有何区别 print命令的值历史 next与step的区别 x命令与print命令的区别 finish until(gdb command) finish and until until可以退出while循环却不能退出for循环 frame(gdb command)
设置断点的四种方式(gdb) breakpoint的三种Disposition Breakpoint Command Lists 在断点处自动执行打印函数 条件断点中使用库函数 普通断点与条件断点的相互转换 在断点之后恢复执行的四种方法 conditional breakpoint and watchpoint 断点和监视点在作用域上的区别
错误的内存访问并不一定会导致段错误 向进程发送一个信号 bash中允许任意大小的转储核心文件 需要转储核心文件的三个场景
info locals
x/14xb multstore
print/t $rip
display/i $rip
ptype
tbreak
Linux内存大页机制(Huge Page,页面大小2M)可提升什么性能?Redis中为什么建议关闭Huge Page?
Huge page对提升TLB命中率比较友好,因为在相同的内存容量下,使用huge page可以减少页表项,TLB就可以缓存更多的页表项,能减少TLB miss的开销。
但是,这个机制对于Redis这种喜欢用fork的系统来说不太友好,尤其是在Redis 的写入请求比较多的情况下。因为fork后,父进程修改数据采用写时复制,复制的粒度为一个内存页。如果只是修改一个256B的数据,父进程需要读原来的内存页,然后再映射到新的物理地址写入。一读一写会造成读写放大。如果内存页越大(例如2MB的大页),那么读写放大也就越严重,对Redis性能造成影响。
July 21, 2022
July 21, 2022
Go 官方提供了 go vet 工具可以用于对 Go 源码做一系列静态检查,在 Go 1.14 版以前默认支持变量遮蔽检查,Go 1.14 版之后,变量遮蔽检查的插件就需要我们单独安装了,安装方法如下:
$go install golang.org/x/tools/go/analysis/passes/shadow/cmd/shadow@latest
go: downloading golang.org/x/tools v0.1.5
go: downloading golang.org/x/mod v0.4.2
一旦安装成功,我们就可以通过 go vet 扫描代码并检查这里面有没有变量遮蔽的问题了。我们现在就来检查一下前面的示例代码,看看效果怎么样。执行检查的命令如下:
$go vet -vettool=$(which shadow) -strict complex.go
./complex.go:13:12: declaration of "err" shadows declaration at line 11
我们看到,go vet 只给出了 err 变量被遮蔽的提示,变量 a 以及预定义标识符 new 被遮蔽的情况并没有给出提示。可以看到,工具确实可以辅助检测,但也不是万能的,不能穷尽找出代码中的所有问题,所以你还是要深入理解代码块与作用域的概念,尽可能在日常编码时就主动规避掉所有遮蔽问题。
July 20, 2022
Go 语言提供了变量声明块用来把多个的变量声明放在一起,并且在语法上也不会限制放置在 var 块中的声明类型,那我们就应该学会充分利用 var 变量声明块,让我们变量声明更规整,更具可读性。
通常,我们会将同一类的变量声明放在一个 var 变量声明块中,不同类的声明放在不同的 var 声明块中,比如下面就是我从标准库 net 包中摘取的两段变量声明代码:
// $GOROOT/src/net/net.go
var (
netGo bool
netCgo bool
)
var (
aLongTimeAgo = time.Unix(1, 0)
noDeadline = time.Time{}
noCancel = (chan struct{})(nil)
)
我们可以将延迟初始化的变量声明放在一个 var 声明块 (比如上面的第一个 var 声明块),然后将声明且显式初始化的变量放在另一个 var 块中(比如上面的第二个 var 声明块),这里我称这种方式为“声明聚类”,声明聚类可以提升代码可读性。
到这里,你可能还会有一个问题:我们是否应该将包级变量的声明全部集中放在源文件头部呢?答案不能一概而论。
使用静态编程语言的开发人员都知道,变量声明最佳实践中还有一条:就近原则。也就是说我们尽可能在靠近第一次使用变量的位置声明这个变量。就近原则实际上也是对变量的作用域最小化的一种实现手段。在 Go 标准库中我们也很容易找到符合就近原则的变量声明的例子,比如下面这段标准库 http 包中的代码就是这样:
// $GOROOT/src/net/http/request.go
var ErrNoCookie = errors.New("http: named cookie not present")
func (r *Request) Cookie(name string) (*Cookie, error) {
for _, c := range readCookies(r.Header, name) {
return c, nil
}
return nil, ErrNoCookie
}
在这个代码块里,ErrNoCookie 这个变量在整个包中仅仅被用在了 Cookie 方法中,因此它被声明在紧邻 Cookie 方法定义的地方。当然了,如果一个包级变量在包内部被多处使用,那么这个变量还是放在源文件头部声明比较适合的。
...
July 20, 2022
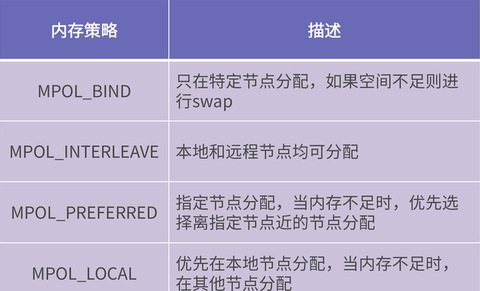
所谓内存策略就是 CPU 访问内存节点的策略,分为先访问本地节点、先访问远程节点、只能访问本地节点等等。内存策略是 libnuma 提供的最主要的功能。现在实现的内存策略主要有 4 种,如下表所示:
 在了解了内存策略之后,我们可以使用 set_mempolicy 接口来对进程的内存策略进行调整,这里用一个实际举例来展示这些 API 的功能。
在了解了内存策略之后,我们可以使用 set_mempolicy 接口来对进程的内存策略进行调整,这里用一个实际举例来展示这些 API 的功能。
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <numa.h>
#include <numaif.h>
#include <unistd.h>
#include <sys/mman.h>
#define N ((1UL << 38) / sizeof(int)) // 128GB
int main() {
uint64_t num_nodes = numa_num_configured_nodes();
uint64_t all_nodes_mask = (1 << numa_num_configured_nodes()) - 1;
uint64_t my_nodes_mask = all_nodes_mask ^ 0b0110;
set_mempolicy(MPOL_BIND, &my_nodes_mask, 1);
// allocate large array and write to it
int *a = malloc(N * sizeof(int));
for (size_t i=1; i < N; i++) {
a[i] = 1;
}
free(a);
return 0;
}
在上面的例子中我们分配了一个比较大的内存,你在实际测试过程中可以根据自己机器上的内存节点大小进行调整即可(修改第 9 行左移的位数),使它接近一个内存节点的空闲内存大小。
你可以在不同机器上使用不同策略(修改代码的第 16 行第一个参数),来验证内存策略的效果。不同架构 CPU 在内存策略上的实现还是有较大的不同的, aarch64 平台和 x86 平台的差异比较明显,如果你有兴趣的话,可以自行尝试。更多关于 libnuma API 的说明可以参考附录给出的文档。
...
July 20, 2022
在多核服务器上,主存也并不是一段平坦的同质的内存。为了加速性能,人们发明了非一致性内存访问(Non-uniform memory access,NUMA),与之对应的是一致性内存访问(Uniform Memory Access, UMA)。
这里的一致性是指,同一个 CPU 对所有内存的访问的速度是一样的,因为物理内存是连续且集中的。而非一致性是指,内存在物理上被分为了多个节点 node, CPU 可以访问所有节点,但是为了提升访问效率,CPU 可以有选择地优先访问离自己近的内存节点。所以在多核处理器上,CPU 也根据内存节点划分成多个组,每个组里的 CPU 访问同一个内存节点的效率是相同的。当然了,任何一个 CPU 都可以访问全部的内存节点,只不过因为“距离”远近的关系,访问效率不一样。
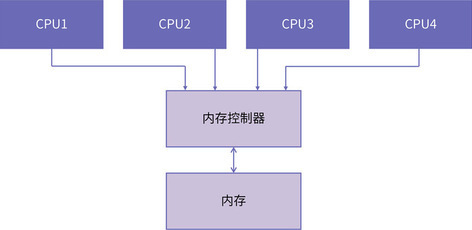
因为 UMA 是基于总线的,CPU 需要先经过前端总线(Front Side Bus,FSB)连接到北桥,然后北桥再连接到内存控制器进行内存访问。如下图所示:
 随着处理器核数的增多,UMA 面临的挑战主要包括两个方面:
随着处理器核数的增多,UMA 面临的挑战主要包括两个方面:
为了解决以上两个问题,NUMA 架构逐渐成为主流。和 UMA 不同,在 NUMA 架构下每个 CPU 现在都有自己的本地内存节点,CPU 与 CPU 之间点对点互联。使用这种方式的典型代表是 intel 的快速通道互联 QPI(Intel QuickPath Interconnect)。如果一个 CPU 要访问远程节点的内存,则先通过 QPI 到达远程节点 CPU 的内存控制器,然后再进行数据传输。
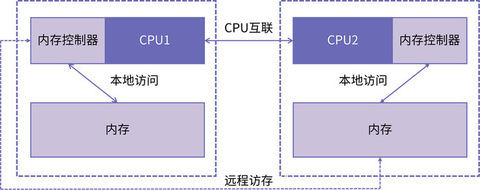 如上图所示,连接到 CPU1 的内存控制器的内存被认为是本地内存。连接到另一个 CPU 插槽 (CPU2) 的内存被视为 CPU1 的外部或远程内存。远程内存访问比本地内存访问有额外的延迟开销,因为它必须遍历互连(点对点链接)并连接到远程内存控制器。由于两者内存位置不同,访问方式也不同,因此这种系统会经历“不均匀”的内存访问时间。
如上图所示,连接到 CPU1 的内存控制器的内存被认为是本地内存。连接到另一个 CPU 插槽 (CPU2) 的内存被视为 CPU1 的外部或远程内存。远程内存访问比本地内存访问有额外的延迟开销,因为它必须遍历互连(点对点链接)并连接到远程内存控制器。由于两者内存位置不同,访问方式也不同,因此这种系统会经历“不均匀”的内存访问时间。
UMA 架构的优点很明显就是结构简单,所有的 CPU 访问内存都是一致的,都必须经过总线。然而它缺点我们再前面也提到了,就是随着处理器核数的增多,总线的带宽压力会越来越大。解决办法就只能扩宽总线,然而成本十分高昂,未来可能仍然面临带宽压力。而 NUMA 在扩展时只需要关注 CPU 之间的连接,不占用总线带宽,自然就成为现代处理器的选择。
...