
半加器 #
我们先来看看,我们人在计算加法的时候一般会怎么操作。二进制的加法和十进制没什么区别,所以我们一样可以用列竖式来计算。我们仍然是从右到左,一位一位进行计算,只是把从逢 10 进 1 变成逢 2 进 1。
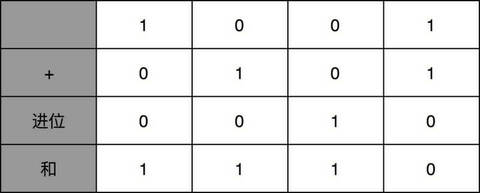 你会发现,其实计算一位数的加法很简单。我们先就看最简单的个位数。输入一共是 4 种组合,00、01、10、11。得到的结果,也不复杂。
你会发现,其实计算一位数的加法很简单。我们先就看最简单的个位数。输入一共是 4 种组合,00、01、10、11。得到的结果,也不复杂。
一方面,我们需要知道,加法计算之后的个位是什么,在输入的两位是 00 和 11 的情况下,对应的输出都应该是 0;在输入的两位是 10 和 01 的情况下,输出都是 1。结果你会发现,这个输入和输出的对应关系,其实就是“异或门(XOR)”。
讲与、或、非门的时候,我们很容易就能和程序里面的“AND(通常是 & 符号)”“ OR(通常是 | 符号)”和“ NOT(通常是 ! 符号)”对应起来。可能你没有想过,为什么我们会需要“异或(XOR)”,这样一个在逻辑运算里面没有出现的形式,作为一个基本电路。其实,异或门就是一个最简单的整数加法,所需要使用的基本门电路。
算完个位的输出还不算完,输入的两位都是 11 的时候,我们还需要向更左侧的一位进行进位。那这个就对应一个与门,也就是有且只有在加数和被加数都是 1 的时候,我们的进位才会是 1。
所以,通过一个异或门计算出个位,通过一个与门计算出是否进位,我们就通过电路算出了一个一位数的加法。于是,我们把两个门电路打包,给它取一个名字,就叫作半加器(Half Adder)。
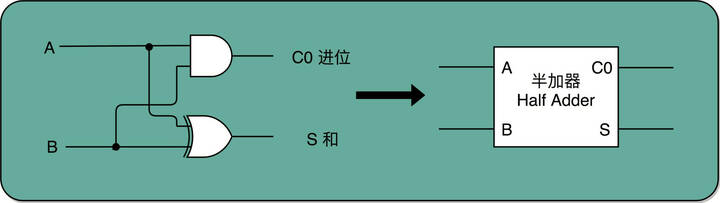 半加器的电路演示
半加器的电路演示
 这些基本的门电路,是我们计算机硬件端的最基本的“积木”,就好像乐高积木里面最简单的小方块。看似不起眼,但是把它们组合起来,最终可以搭出一个星球大战里面千年隼这样的大玩意儿。我们今天包含十亿级别晶体管的现代 CPU,都是由这样一个一个的门电路组合而成的。
这些基本的门电路,是我们计算机硬件端的最基本的“积木”,就好像乐高积木里面最简单的小方块。看似不起眼,但是把它们组合起来,最终可以搭出一个星球大战里面千年隼这样的大玩意儿。我们今天包含十亿级别晶体管的现代 CPU,都是由这样一个一个的门电路组合而成的。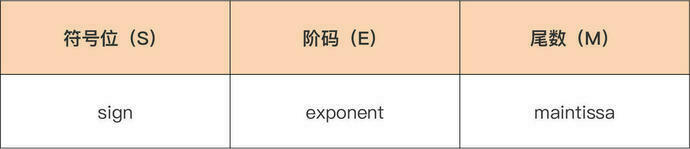 我们看到浮点数在内存中的二进制表示分三个部分:符号位、阶码(即经过换算的指数),以及尾数。这样表示的一个浮点数,它的值等于:
我们看到浮点数在内存中的二进制表示分三个部分:符号位、阶码(即经过换算的指数),以及尾数。这样表示的一个浮点数,它的值等于:
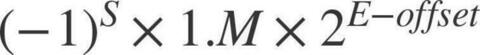 其中浮点值的符号由符号位决定:当符号位为 1 时,浮点值为负值;当符号位为 0 时,浮点值为正值。公式中 offset 被称为阶码偏移值。
其中浮点值的符号由符号位决定:当符号位为 1 时,浮点值为负值;当符号位为 0 时,浮点值为正值。公式中 offset 被称为阶码偏移值。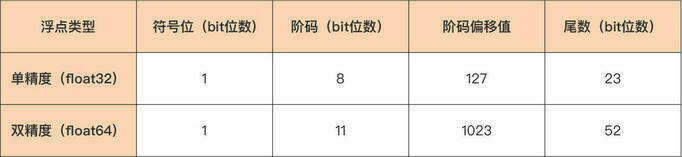 我们看到,单精度浮点类型(float32)为符号位分配了 1 个 bit,为阶码分配了 8 个 bit,剩下的 23 个 bit 分给了尾数。而双精度浮点类型,除了符号位的长度与单精度一样之外,其余两个部分的长度都要远大于单精度浮点型,阶码可用的 bit 位数量为 11,尾数则更是拥有了 52 个 bit 位。
我们看到,单精度浮点类型(float32)为符号位分配了 1 个 bit,为阶码分配了 8 个 bit,剩下的 23 个 bit 分给了尾数。而双精度浮点类型,除了符号位的长度与单精度一样之外,其余两个部分的长度都要远大于单精度浮点型,阶码可用的 bit 位数量为 11,尾数则更是拥有了 52 个 bit 位。