
iota #
iota 是 Go 语言的一个预定义标识符,它表示的是 const 声明块(包括单行声明)中,每个常量所处位置在块中的偏移值(从零开始)。同时,每一行中的 iota 自身也是一个无类型常量,可以像前面我们提到的无类型常量那样,自动参与到不同类型的求值过程中来,不需要我们再对它进行显式转型操作。
你可以看看下面这个 Go 标准库中 sync/mutex.go 中的一段基于 iota 的枚举常量的定义:
// $GOROOT/src/sync/mutex.go
const (
mutexLocked = 1 << iota
mutexWoken
mutexStarving
mutexWaiterShift = iota
starvationThresholdNs = 1e6
)
首先,这个 const 声明块的第一行是 mutexLocked = 1 << iota ,iota 的值是这行在 const 块中的偏移,因此 iota 的值为 0,我们得到 mutexLocked 这个常量的值为 1 << 0,也就是 1。
第二行:mutexWorken 。因为这个 const 声明块中并没有显式的常量初始化表达式,所以我们根据 const 声明块里“隐式重复前一个非空表达式”的机制,这一行就等价于 mutexWorken = 1 << iota。而且,又因为这一行是 const 块中的第二行,所以它的偏移量 iota 的值为 1,我们得到 mutexWorken 这个常量的值为 1 << 1,也就是 2。
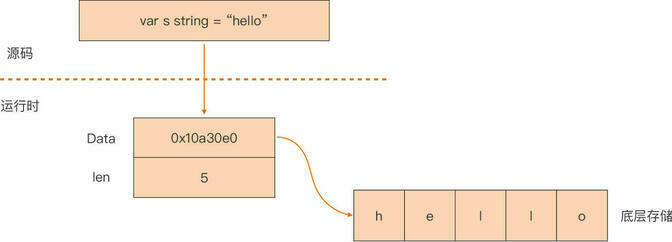
...
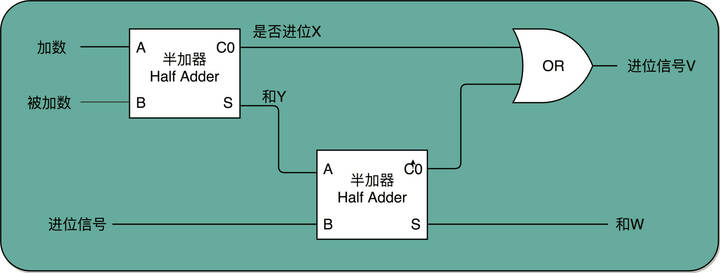 全加器就是两个半加器加上一个或门
全加器就是两个半加器加上一个或门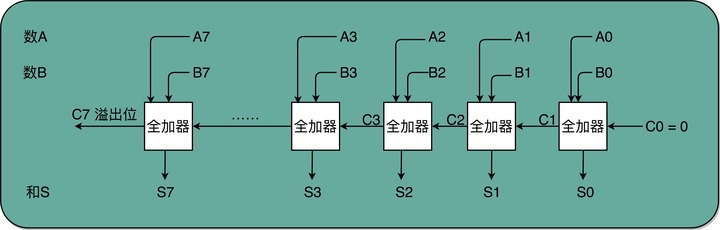 8 位加法器可以由 8 个全加器串联而成
8 位加法器可以由 8 个全加器串联而成