
使用forwarding指针的深度优先GC算法 #
复制 GC 算法,最核心的就是如何实现复制。我们自己就可以很容易地写出一个基于深度优先搜索的算法,它的伪代码如下所示:
void copy_gc() {
for (obj in roots) {
*obj = copy(obj);
}
}
obj * copy(obj) {
new_obj = to_space.allocate(obj.size);
copy_data(new_obj, obj, size);
for (child in obj) {
*child = copy(child);
}
return new_obj;
}
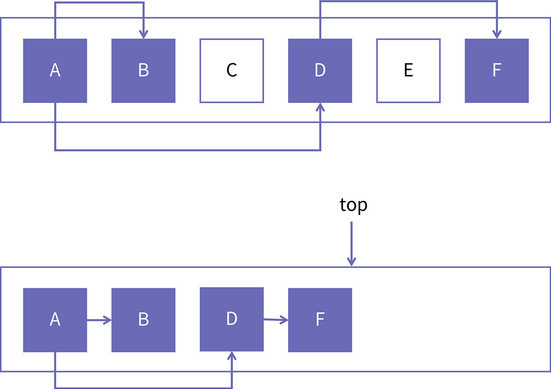
上面的代码中缺少了对重复访问对象的判断。考虑到有两个对象 A 和 B,它们都引用了对象 C,而且它们都是活跃对象,现在我们对这个图进行深度优先遍历。
 在遍历过程中,A 先拷到 to space,然后 C 又拷过去,这时候,空间里的引用是这种状态:
在遍历过程中,A 先拷到 to space,然后 C 又拷过去,这时候,空间里的引用是这种状态:
 A 和 C 都拷到新的空间里了,原来的引用关系还是正确的。但我们的算法在拷贝 B 对象的时候,先完成 B 的拷贝,然后你就会发现,此时我们还会把 C 再拷贝一次。这样,在 To 空间里就会有两个 C 对象了,这显然是错的。我们必须要想办法解决这个问题。
A 和 C 都拷到新的空间里了,原来的引用关系还是正确的。但我们的算法在拷贝 B 对象的时候,先完成 B 的拷贝,然后你就会发现,此时我们还会把 C 再拷贝一次。这样,在 To 空间里就会有两个 C 对象了,这显然是错的。我们必须要想办法解决这个问题。
通常来说,在一般的深度优先搜索算法中,我们只需要为每个结点增加一个标志位 visited,以表示这个结点是否被访问过。但这只能解决重复访问的问题,还有一件事情我们没有做到:新空间中 B 对象对 C 对象的引用没有修改。这是因为我们在对 B 进行拷贝的时候,并不知道它所引用的对象在新空间中的地址。
... 可以看到,上图中的 from 空间已经满了,这时候,如果想再创建一个新的对象是无法满足的。此时就会执行 GC 算法将活跃对象都拷贝到新的空间中去。
可以看到,上图中的 from 空间已经满了,这时候,如果想再创建一个新的对象是无法满足的。此时就会执行 GC 算法将活跃对象都拷贝到新的空间中去。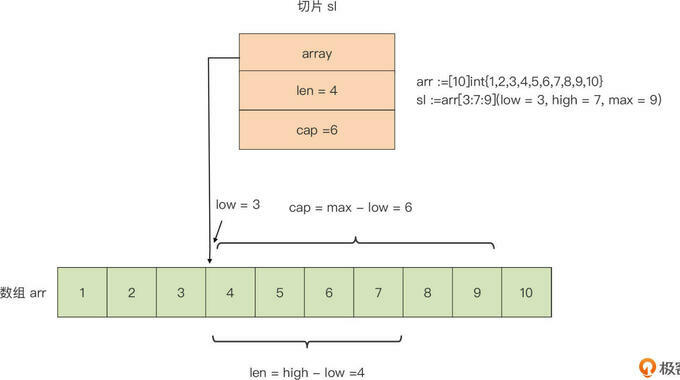 我们看到,基于数组创建的切片,它的起始元素从 low 所标识的下标值开始,切片的长度(len)是 high - low,它的容量是 max - low。而且,由于切片
sl 的底层数组就是数组 arr,对切片 sl 中元素的修改将直接影响数组 arr 变量。比如,如果我们将切片的第一个元素加 10,那么数组 arr 的第四个元素将变为 14:
我们看到,基于数组创建的切片,它的起始元素从 low 所标识的下标值开始,切片的长度(len)是 high - low,它的容量是 max - low。而且,由于切片
sl 的底层数组就是数组 arr,对切片 sl 中元素的修改将直接影响数组 arr 变量。比如,如果我们将切片的第一个元素加 10,那么数组 arr 的第四个元素将变为 14: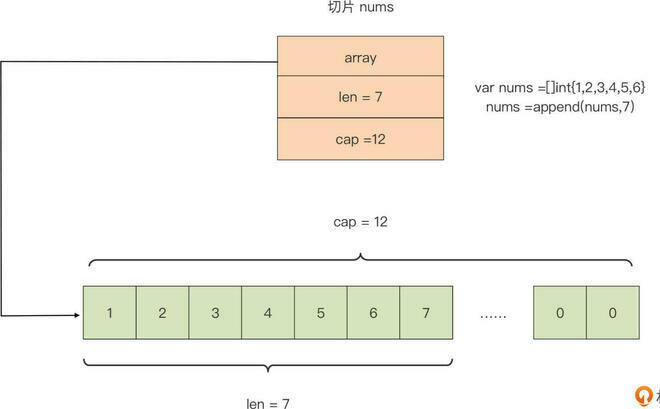 我们看到,Go 编译器会自动为每个新创建的切片,建立一个底层数组,默认底层数组的长度与切片初始元素个数相同。
我们看到,Go 编译器会自动为每个新创建的切片,建立一个底层数组,默认底层数组的长度与切片初始元素个数相同。