省略字面值中的元素类型
#
这里我们再看看怎么通过稍微复杂一些的复合字面值,对 map 类型变量进行初始化:
m1 := map[int][]string{
1: []string{"val1_1", "val1_2"},
3: []string{"val3_1", "val3_2", "val3_3"},
7: []string{"val7_1"},
}
type Position struct {
x float64
y float64
}
m2 := map[Position]string{
Position{29.935523, 52.568915}: "school",
Position{25.352594, 113.304361}: "shopping-mall",
Position{73.224455, 111.804306}: "hospital",
}
上面代码虽然完成了对两个 map 类型变量 m1 和 m2 的显式初始化,但作为初值的字面值似乎有些“臃肿”。针对这种情况,Go 提供了“语法糖”。这种情况下,Go 允许省略字面值中的元素类型。因为 map 类型表示中包含了 key 和 value 的元素类型,Go 编译器已经有足够的信息,来推导出字面值中各个值的类型了。我们以 m2 为例,这里的显式初始化代码和上面变量 m2 的初始化代码是等价的:
m2 := map[Position]string{
{29.935523, 52.568915}: "school",
{25.352594, 113.304361}: "shopping-mall",
{73.224455, 111.804306}: "hospital",
}
以后在无特殊说明的情况下,我们都将使用这种简化后的字面值初始化方式。
Viewpoint
#
From
#
16|复合数据类型:原生map类型的实现机制是怎样的?
Links
#

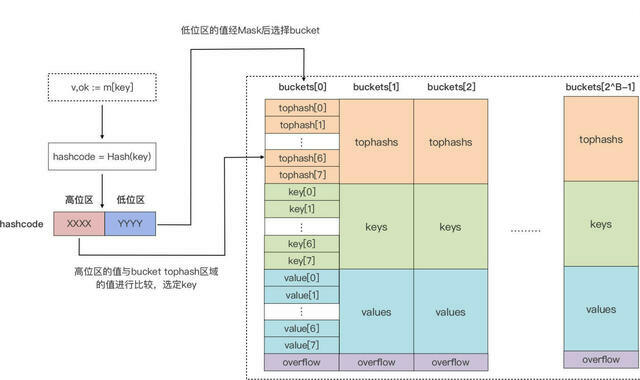 因此,每个 bucket 的 tophash 区域其实是用来快速定位 key 位置的,这样就避免了逐个 key 进行比较这种代价较大的操作。尤其是当 key 是 size 较大的字符串类型时,好处就更突出了。这是一种以空间换时间的思路。
因此,每个 bucket 的 tophash 区域其实是用来快速定位 key 位置的,这样就避免了逐个 key 进行比较这种代价较大的操作。尤其是当 key 是 size 较大的字符串类型时,好处就更突出了。这是一种以空间换时间的思路。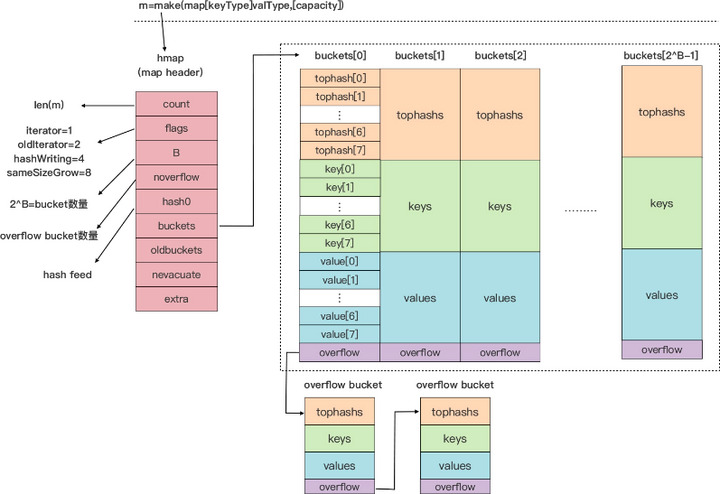
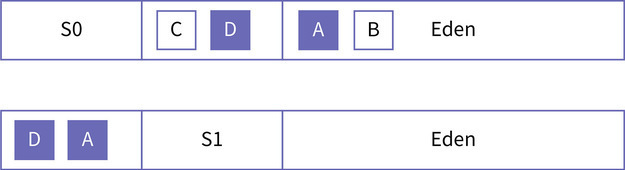 在这张图里,Hotspot 的内存管理器在 Eden 空间中分配新的对象,每次 GC 时,如果将 S0 做为 To 空间,则 S1 与 Eden 合起来成为 From 空间。也就是说
To 空间这个空闲区域就大大减小了,这样可以提升空间的总体利用率。
在这张图里,Hotspot 的内存管理器在 Eden 空间中分配新的对象,每次 GC 时,如果将 S0 做为 To 空间,则 S1 与 Eden 合起来成为 From 空间。也就是说
To 空间这个空闲区域就大大减小了,这样可以提升空间的总体利用率。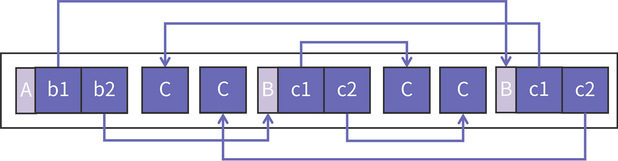 请你注意,图中的空白部分是我为了让图更容易查看而故意加的,真实的情况是每个对象之间的空白是不存在的,它们是紧紧地挨在一起的。
请你注意,图中的空白部分是我为了让图更容易查看而故意加的,真实的情况是每个对象之间的空白是不存在的,它们是紧紧地挨在一起的。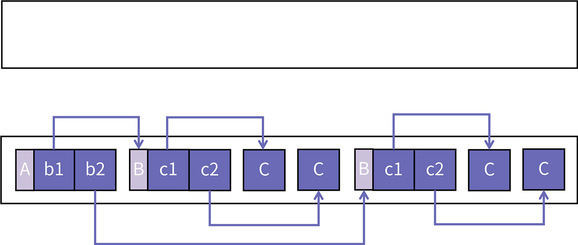 从上面的图片中可以观察到一个特点:To 空间中的对象排列顺序和 From 空间中的对象排列顺序发生了变化。具有引用关系的对象在新空间中距离更近了。
从上面的图片中可以观察到一个特点:To 空间中的对象排列顺序和 From 空间中的对象排列顺序发生了变化。具有引用关系的对象在新空间中距离更近了。