语法 #
只读变量与常量 类型转换与数据的实际存储 查看C语言表达式的抽象语法树 定义完备的多语句宏函数 dangling pointer 自定义数据对齐 常见的C语言调用惯例
指针 #
宏 #
性能 #
restrict 关键字 消除不必要的内存引用 循环展开 达夫设备 Duff’s Device
安全 #
有符号数隐式转换为无符号数导致的错误 函数getpeername的安全漏洞
术语 #
VAS - Virtual Address Space
 July 28, 2022
July 28, 2022
只读变量与常量 类型转换与数据的实际存储 查看C语言表达式的抽象语法树 定义完备的多语句宏函数 dangling pointer 自定义数据对齐 常见的C语言调用惯例
restrict 关键字 消除不必要的内存引用 循环展开 达夫设备 Duff’s Device
有符号数隐式转换为无符号数导致的错误 函数getpeername的安全漏洞
VAS - Virtual Address Space
July 28, 2022
在 C 语言中,通过内联方式直接写到源代码中的字面量值一般被称为“常量”。
我们在前面提到过常量的一个性质,即“它们被定义后无法被再次修改”。这也就意味着,这些常量数据无法灵活地被开发者操控,它们只能在程序最开始出现的地方发挥作用。比如在前面定义变量的一系列代码中,出现的 “-10”、“2.0” 等数字值便是常量。这些值在被拷贝并赋值给相应的变量后便结束了使命。
用 const 关键字按照与定义变量相同语法定义的量,不也是常量吗?它与字面量常量有什么区别呢?
一般来说,我们会按照下面的方式使用 const 关键字:
const int vx = 10;
const int* px = &vx;
通常来说,在 C 语言中,使用 const 关键字修饰的变量定义语句,表示对于这些变量,我们无法在后续的程序中修改其对应或指针指向的值。因此,我们更倾向于称它们为“只读变量”,而非常量。当然,在程序的外在表现上,二者有一点是相同的:其值在第一次出现时便被确定,且无法在后续程序中被修改。
只读变量与字面量常量的一个最重要的不同点是,使用 const 修饰的只读变量不具有“常量表达式”的属性,因此无法用来表示定长数组大小,或使用在 case 语句中。常量表达式本身会在程序编译时被求值,而只读变量的值只能够在程序实际运行时才被得知。并且,编译器通常不会对只读变量进行内联处理,因此其求值不符合常量表达式的特征。
误用只读变量和常量会导致编译错误,下面这段代码展示了这类错误:
#include <stdio.h>
int main(void) {
const int vx = 10;
const int vy = 10;
int arr[vx] = {1, 2, 3}; // [错误1] 使用非常量表达式定义定长数组;
switch(vy) {
case vx: { // [错误2] 非常量表达式应用于 case 语句;
printf("Value matched!");
break;
}
}
}
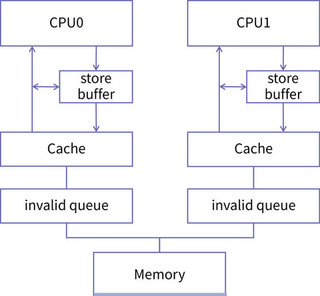
当一个 CPU 向同伴发出 Invalid 消息的时候,它的同伴要先把自己的缓存置为 Invalid,然后再发出 acknowledgement。这个从“把缓存置为 Invalid”到“发出 acknowledgement”的过程所需要的时间也是比较长的。
而且,由于 store buffer 的存在提升了写入速度,那么 invalid 消息确认速度相比起来就慢了,这就带来了速度的不匹配,很容易导致 store buffer 的内容还没有及时更新到 cache 里,自己的容量就被撑爆了,从而失去了加速的作用。
为了解决这个问题,CPU 设计者又引入了“invalid queue”,也就是失效队列这个结构。加入了这个结构后,收到 Invalid 消息的 CPU,比如我们称它为 CPU1,在收到 Invalid 消息时立即向 CPU0 发回确认消息,但这个时候 CPU1 并没有把自己的 cache 由 Share 置为 Invalid,而是把这个失效的消息放到一个队列中,等到空闲的时候再去处理失效消息,这个队列就是 invalid queue。
经过这样的改进后,CPU1 响应失效消息的速度大大提升了,带有 invalid
queue 的缓存结构是这样的:
July 28, 2022
当存在store buffer的情况下。针对写操作,CPU直接把数据扔给store buffer。后续store buffer负责以FIFO次序写回L1 Cache。这会对我们的程序产生什么影响呢?我们来看个例子。
static int x = 0, y = 0;
static int r1, r2;
static void int thread_cpu0(void)
{
x = 1; /* 1) */
r1 = y; /* 2) */
}
static void int thread_cpu1(void)
{
y = 1; /* 3) */
r2 = x; /* 4) */
}
static void check_after_assign(void)
{
printk("r1 = %d, r2 = %d\n", r1, r2);
}
假设thread_cpu0在CPU0上执行,thread_cpu1在CPU1上执行。在多核系统上,我们知道两个函数4条操作执行可以互相交错。理论上来我们有以下6种排列组合。
当我们确保thread_cpu0和thread_cpu1执行完成后,调用check_after_assign() 会打印什么提示信息呢?根据以上6种组合,我们可能会得到如下3种结果。 r1 = 1, r2 = 1 r1 = 0, r2 = 1 r1 = 1, r2 = 0 这个结果是符合我们的认知的。不过,当考虑store buffer时,有可能会出现如下结果: r1 = 0, r2 = 0
...
July 27, 2022
在一些“积少成多”的计算过程中,比如在机器学习中,我们经常要计算海量样本计算出来的梯度或者 loss,于是会出现几亿个浮点数的相加。每个浮点数可能都差不多大,但是随着累积值的越来越大,就会出现“大数吃小数”的情况。
我们可以做一个简单的实验,用一个循环相加 2000 万个 1.0f,最终的结果会是 1600 万左右,而不是 2000 万。这是因为,加到 1600 万之后的加法因为精度丢失都没有了。这个代码比起上面的使用 2000 万来加 1.0 更具有现实意义。
public class FloatPrecision {
public static void main(String[] args) {
float sum = 0.0f;
for (int i = 0; i < 20000000; i++) {
float x = 1.0f;
sum += x;
}
System.out.println("sum is " + sum);
}
}
对应的输出结果是:
sum is 1.6777216E7
可以用Kahan Summation的算法来解决这个问题。
public class KahanSummation {
public static void main(String[] args) {
float sum = 0.0f;
float c = 0.0f;
for (int i = 0; i < 20000000; i++) {
float x = 1.0f;
float y = x - c;
float t = sum + y;
c = (t-sum)-y;
sum = t;
}
System.out.println("sum is " + sum);
}
}
对应的输出结果就是:
...
July 27, 2022
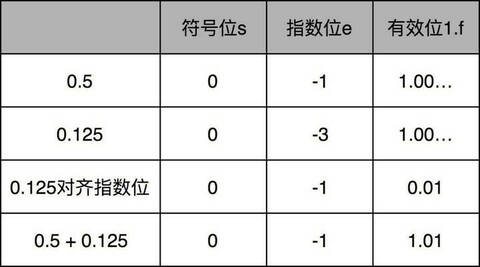
浮点数的加法原理,记住六个字就行了,那就是先对齐、再计算。两个浮点数的指数位可能是不一样的,所以我们要把两个的指数位,变成一样的,然后只去计算有效位的加法就好了。
比如 0.5,表示成浮点数,对应的指数位是 -1,有效位是 00…(后面全是 0,记住 f 前默认有一个 1)。0.125 表示成浮点数,对应的指数位是 -3,有效位也还是 00…(后面全是 0,记住 f 前默认有一个 1)。
那我们在计算 0.5+0.125 的浮点数运算的时候,首先要把两个的指数位对齐,也就是把指数位都统一成两个其中较大的 -1。对应的有效位 1.00…也要对应右移两位,因为 f 前面有一个默认的 1,所以就会变成 0.01。然后我们计算两者相加的有效位 1.f,就变成了有效位 1.01,而指数位是 -1,这样就得到了我们想要的加法后的结果。
实现这样一个加法,也只需要位移。和整数加法类似的半加器和全加器的方法就能够实现,在电路层面,也并没有引入太多新的复杂性。
回到浮点数的加法过程,你会发现,其中指数位较小的数,需要在有效位进行右移,在右移的过程中,最右侧的有效位就被丢弃掉了。这会导致对应的指数位较小的数,在加法发生之前,就丢失精度。两个相加数的指数位差的越大,位移的位数越大,可能丢失的精度也就越大。当然,也有可能你的运气非常好,右移丢失的有效位都是 0。这种情况下,对应的加法虽然丢失了需要加的数字的精度,但是因为对应的值都是 0,实际的加法的数值结果不会有精度损失。
32 位浮点数的有效位长度一共只有 23 位,如果两个数的指数位差出 23 位,较小的数右移 24 位之后,所有的有效位就都丢失了。这也就意味着,虽然浮点数可以表示上到 3.40×1038,下到 1.17×10−38 这样的数值范围。但是在实际计算的时候,只要两个数,差出 224,也就是差不多 1600 万倍,那这两个数相加之后,结果完全不会变化。
你可以试一下,我下面用一个简单的 Java 程序,让一个值为 2000 万的 32 位浮点数和 1 相加,你会发现,+1 这个过程因为精度损失,被“完全抛弃”了。
public class FloatPrecision {
public static void main(String[] args) {
float a = 20000000.0f;
float b = 1.0f;
float c = a + b;
System.out.println("c is " + c);
float d = c - a;
System.out.println("d is " + d);
}
}
对应的输出结果就是:
...
July 27, 2022
CPU 的设计者为每个核都添加了一个名为 store buffer 的结构,store buffer 是硬件实现的缓冲区,它的读写速度比缓存的速度更快,所有面向缓存的写操作都会先经过 store buffer。
store buffer会收集多次写操作,然后在合适的时机进行提交。增加了 store
buffer 以后的 CPU 缓存结构是这样的:
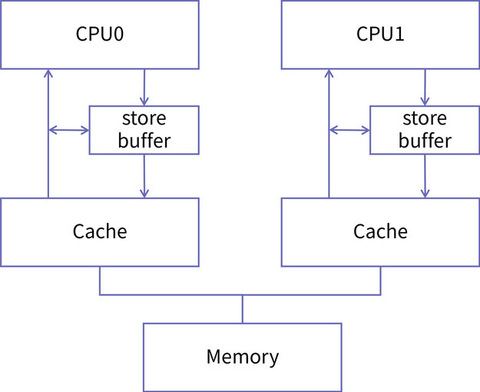 在这样的结构里,如果 CPU 的某个核再要对一个变量进行赋值,它就不必等到所有的同伴都确认完,而是直接把新的值放入 store buffer,然后再由 store
buffer 慢慢地去做核间同步,并且将新的值刷入到 cache 中去就好了。而且,每个核的 store buffer 都是私有的,其他核不可见。
在这样的结构里,如果 CPU 的某个核再要对一个变量进行赋值,它就不必等到所有的同伴都确认完,而是直接把新的值放入 store buffer,然后再由 store
buffer 慢慢地去做核间同步,并且将新的值刷入到 cache 中去就好了。而且,每个核的 store buffer 都是私有的,其他核不可见。
我们现在来举个例子。我们使用两个 CPU,分别叫做 CPU0 和 CPU1,其中 CPU0 负责写数据,而 CPU1 负责读数据,我们看看在增加了 store buffer 这个结构以后,它们在进行核间同步时会遇到什么问题。
假如 CPU0 刚刚更新了变量 a 的值,并且将它放到了 store buffer 中,CPU0 自己接着又要读取 a 的值,此时,它会在自己的 store buffer 中读到正确的值。
那如果在这一次修改的 a 值被写入 cache 之前,CPU0 又一次对 a 值进行了修改呢?那也没问题,这次更新就可以直接写入 store buffer。因为 store buffer 是 CPU0 私有的,修改它不涉及任何核间同步和缓存一致性问题,所以效率也得到了比较大的提升。
...
July 26, 2022
我们可以将结点分为三类:
并发标记中最严重的问题就是漏标。如果一个对象是活跃对象,但它没有被标记,这就是漏标。这就会出现活跃对象被回收的情况。例如下图中所示:
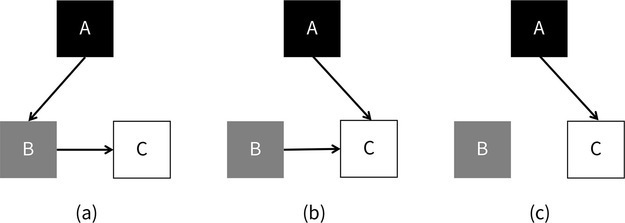
在上图中的最左边,标号(a)的子图中,一切都还是正常的,B 尚未扩展,在 B 扩展的时候,C 自然可以被标记。在(b)中,A 出发的引用指向了 C,这时由于 B 指向 C 的引用还存在,仍然没有什么问题。但在(c)中,B 指向 C 的引用消失了,因为 A 已经变成黑色,不会再被扩展了,所以 C 就没有机会再被标记了。这就产生了漏标。
总的来说,黑色对象引用了白色对象,而白色对象又没有其他机会再被访问到,所以白色对象就被漏标了。
July 26, 2022
July 26, 2022