什么是编程语言的“一等公民”呢? #
关于这个名词,业界和教科书都没有给出精准的定义。我们这里可以引用一下 wiki 发明人、C2 站点作者沃德·坎宁安 (Ward Cunningham)对“一等公民”的解释:
如果一门编程语言对某种语言元素的创建和使用没有限制,我们可以像对待值(value)一样对待这种语法元素,那么我们就称这种语法元素是这门编程语言的“一等公民”。拥有“一等公民”待遇的语法元素可以存储在变量中,可以作为参数传递给函数,可以在函数内部创建并可以作为返回值从函数返回。
 July 31, 2022
July 31, 2022
July 31, 2022
July 31, 2022
当函数的返回值个数较多时,每次显式使用 return 语句时都会接一长串返回值,这时,我们用具名返回值可以让函数实现的可读性更好一些,比如下面 Go 标准库 time 包中的 parseNanoseconds 函数就是这样:
// $GOROOT/src/time/format.go
func parseNanoseconds(value string, nbytes int) (ns int, rangeErrString string, err error) {
if !commaOrPeriod(value[0]) {
err = errBad
return
}
if ns, err = atoi(value[1:nbytes]); err != nil {
return
}
if ns < 0 || 1e9 <= ns {
rangeErrString = "fractional second"
return
}
scaleDigits := 10 - nbytes
for i := 0; i < scaleDigits; i++ {
ns *= 10
}
return
}
像 G1 这种分区回收算法,有些 Region 可能被选入 CSet( 回收集合CollectionSet),有些则不会。所以,我们需要知道当一个 Region 需要被回收时,有哪些其他的 Region 引用了自己。相应地,为了加快定位速度,分区回收算法为每个 Region 都引入了记录集(Remembered Set,RSet),每个 Region 都有自己的专属 RSet。
和 Card table 不同的是,RSet 记录谁引用了我,这种记录集被人们称为
point-in 型的,而 Card table 则记录我引用了谁,这种记录集被称为
point-out 型。
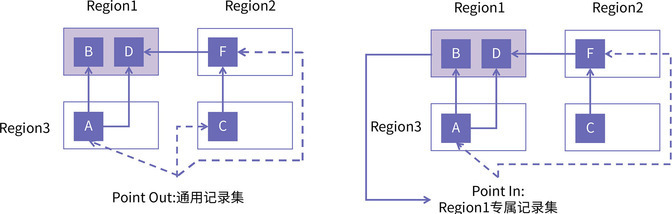
图的左侧为Card Table,展示了一个维护跨区引用的通用记录集,它是全局唯一的,记录了每个Region对其他Region的引用,为Point Out型 。
图右侧展示了 Region1 的专属记录集,记录的是哪些Region引用了Region1。
July 31, 2022
G1 的垃圾回收模式有两种:分别是 young GC 和 mixed GC。
无论是 young GC 还是 mixed GC,都会回收全部的年轻代,mixed 回收的老年代 Region 是需要进行决策的(Humongous 在回收时也是当做老年代的 Region 处理的)。那么决定老年代 Region 是否被回收的因素具体有哪些呢?
我们把 mixed GC 中选取的老年代对象 Region 的集合称之为回收集合(Collection Set,CSet)。CSet 的选取要素有以下两点:
MaxGCPauseMillis 默认是 200ms,一般不需要进行调整,如果需要停顿时间更短可以对它进行设置,不过需要注意的是,MaxGCPauseMillis 设置的越小,选取的老年代 Region 就会越少,如果 GC 压力居高不下,就会触发 G1 的 Full GC。
触发 G1 的 Full GC 代价是很高的。最早的实现是一个单线程的 Mark-Compact GC,停顿时间非常长,虽然后来也改进成多线程,但还是需要尽量避免触发 G1 的 Full GC。如果一个应用会频繁触发 G1 GC 的 Full GC,那么说明这个应用的 GC 参数配置是不合理的,理想情况下 G1 是没有 Full GC 的。
...
July 31, 2022
解决活跃对象漏标的问题的两种常见的方法,分别是“往前走”和“往后退一步”。还有第三种解法,这是由日本学者汤浅太一提出的,具体的算法如下图所示:
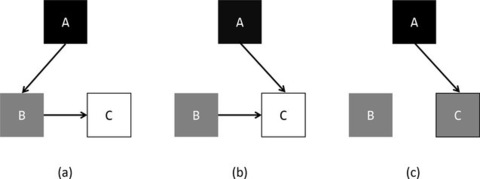 在这张图中,我们可以看到,当对象 B 对 C 的引用关系消失以后,再将 C 标记为灰色,即便将来 A 对 C 的引用消失了,也会在当前 GC 周期内被视为活跃对象。也就是说,C 有可能变成浮动垃圾。我们把这种在删除引用的时候进行维护的屏障叫做 deletion barrier。
在这张图中,我们可以看到,当对象 B 对 C 的引用关系消失以后,再将 C 标记为灰色,即便将来 A 对 C 的引用消失了,也会在当前 GC 周期内被视为活跃对象。也就是说,C 有可能变成浮动垃圾。我们把这种在删除引用的时候进行维护的屏障叫做 deletion barrier。
G1 中采用的就是这种做法。这种做法的特点是,在 GC 标记开始的一瞬间,活跃的对象无论在标记期间发生怎样的变化,都会被认为是活跃的对象。
我们知道,当一个对象的全部引用被删除时,才会被当做垃圾。而如果使用我们前面讲到的 deletion barrier,在并发标记阶段,即便对象的全部引用被删除,也会被当做活跃对象来处理。就好像在 GC 开始的瞬间,内存管理器为所有活跃对象做了一个快照一样,所以人们给了这种技术一个很形象的名字:开始时快照(Snapshot At The Beginning,SATB)。
你要注意的是,有些文章对 SATB 的解释是:在 GC 开始时将堆做一个内存快照,存放到磁盘上。这种说法就是望文生义了。因为快照这个词在计算机领域通常是指压缩,索引等技术,所以就有人把这里的快照理解成了对堆对象的一种压缩。由此,我们就知道这种错误的说法是怎么来的了。
当 B 对象对 C 对象的引用消失时,C 对象将会被标记为灰色。这个动作的效率是比较低的,如果都放在写屏障中做,会极大地影响程序性能。因为写屏障的逻辑是由业务线程执行的。
为了解决这个问题,GC 开发者将“C 对象标记为灰色”这件事情往后推迟了。业务线程只需要把 C 对象记录到一个本地队列中就可以了。每个业务线程都有一个这样的线程本地队列,它的名字是 SATB 队列。
当业务线程发现对象 C 的引用被删除之后,直接将 C 放到 SATB 队列中,并不去做标记,真正做标记的工作交给 GC 线程去做,这样就减少了写屏障的开销。
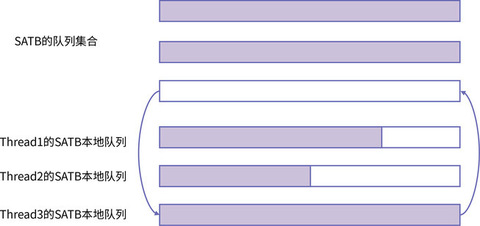
如上图所示,每个线程有自己的本地 SATB 队列,当本地队列满了之后,就把它交给 SATB 队列集合,然后再领取一个空队列当做线程的本地 SATB 队列。GC 线程则会将 SATB 队列集合中的对象标记为灰色,至于什么时候标记,并不需要业务线程关心。
...
July 31, 2022
我们来了解一下分区回收算法的堆空间是如何划分的。下图是 G1 GC 的堆结构:
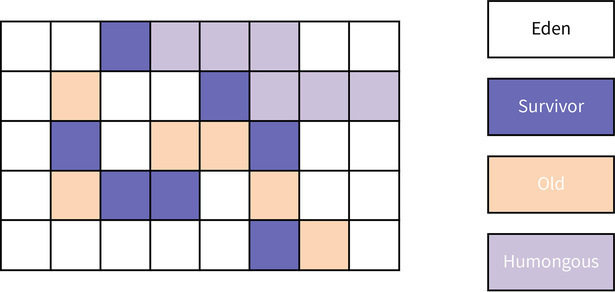 G1 也是一个分代的垃圾回收算法,不过,和之前介绍的 CMS、Scavenge 算法不同的是:G1 的老年代和年轻代不再是一块连续的空间,整个堆被划分成若干个大小相同的 Region,也就是区。Region 的类型有 Eden、Survivor、Old、
Humongous 四种,而且每个 Region 都可以单独进行管理。
G1 也是一个分代的垃圾回收算法,不过,和之前介绍的 CMS、Scavenge 算法不同的是:G1 的老年代和年轻代不再是一块连续的空间,整个堆被划分成若干个大小相同的 Region,也就是区。Region 的类型有 Eden、Survivor、Old、
Humongous 四种,而且每个 Region 都可以单独进行管理。
Humongous 是用来存放大对象的,如果一个对象的大小大于一个 Region 的 50% (默认值),那么我们就认为这个对象是一个大对象。为了防止大对象的频繁拷贝,我们可以将大对象直接放到 Humongous 中。
而 Eden、Survivor、Old 三种区域和我们前面课程中介绍的 Eden 分区、 Survivor 分区以及老年代的作用是类似的。也就是说,对象会在 Eden Regions 中分配,当进行年轻代 GC 时,会将活跃对象拷贝到 Survivor Regions;当对象年龄超过晋升阈值时,就把活跃对象复制进 Old Regions。
July 30, 2022
你先来看看下面这个代码:
// CPU0
void foo() {
a = 1;
b = 1;
}
// CPU1
void bar() {
while (b == 0) continue;
assert(a == 1);
}
假如,CPU0 和 CPU1 的缓存中都有变量 a 的副本,也就是说变量 a 所对应的缓存行在 CPU0 和 CPU1 中都是 Share 状态。CPU1 中没有变量 b 的副本,b 所对应缓存在 CPU0 中是 Exclusive 状态。
当 CPU0 在将变量 a 写入缓存的时候,会产生 Invalid 消息,这个消息到达 CPU1 以后,CPU1 不再立即处理它了,而是将这个消息放入 invalid queue,并且立即向 CPU0 回复了 invalid acknowledgement 消息。
CPU0 在得到这个确认消息以后,就可以独占该缓存了,直接将这块缓存变为 Modified 状态,然后把 a 写入。在 a 写入以后,foo 函数中的内存屏障就可以顺利通过了,接下来就可以写入变量 b 的新值。由于 b 是 Exclusive 的,它的更新比较简单,你可以自己思考一下。
...
July 30, 2022
CPU Store Buffer 的存在是为提升写性能,放弃了缓存的顺序一致性,我们把这种现象称为弱缓存一致性。在正常的程序中,多个 CPU 一起操作同一个变量的情况是比较少的,所以 store buffer 可以大大提升程序的运行性能。但在需要核间同步的情况下,我们还是需要这种一致性的,这就需要软件工程师自己在合适的地方添加内存屏障了。
store buffer并不能保证变量写入缓存和主存的顺序,你先来看看下面这个代码:
// CPU0
void foo() {
a = 1;
b = 1;
}
// CPU1
void bar() {
while (b == 0) continue;
assert(a == 1);
}
在这个代码块中,CPU0 执行 foo 函数,CPU1 执行 bar 函数。但在对变量 a 和 b 进行赋值的时候,有两种情况会导致它们的赋值顺序被打乱。
这种情况完全是有可能的。如果 a 是 Share 状态,b 是 Exclusive 状态,那么尽管 CPU0 在执行时没有乱序,这两个变量由 store buffer 写入缓存时也是不能保证顺序的。
那这个时候,我们假设 CPU1 开始执行时,a 和 b 所对应的缓存行都是 Invalid 状态。当 CPU1 开始执行第 9 行的时候,由于 b 所对应的缓存区域是 Invalid 状态,它就会向总线发出 BusRd 请求,那么 CPU1 就会先把 b 的最新值读到本地,完成变量 b 的值的更新,从而跳出while的循环,继续执行assert 语句。
...
July 30, 2022
下面这个电路在 RS触发器基础之上,在 R 和 S 开关之后,加入了两个与门,同时给这两个与门加入了一个时钟信号 CLK 作为电路输入。
这样,当时钟信号 CLK 在低电平的时候,与门的输入里有一个 0,两个实际的 R 和 S 后的与门的输出必然是 0。也就是说,无论我们怎么按 R 和 S 的开关,根据 R-S 触发器的真值表,对应的 Q 的输出都不会发生变化。
只有当时钟信号 CLK 在高电平的时候,与门的一个输入是 1,输出结果完全取决于 R 和 S 的开关。我们可以在这个时候,通过开关 R 和 S,来决定对应 Q
的输出。
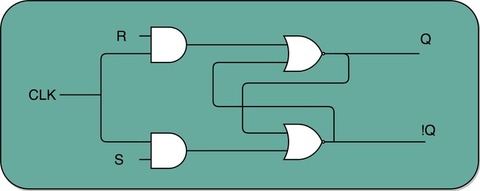 通过一个时钟信号,我们可以在特定的时间对输出的 Q 进行写入操作
通过一个时钟信号,我们可以在特定的时间对输出的 Q 进行写入操作
如果这个时候,我们让 R 和 S 的开关,也用一个反相器连起来,也就是通过同一个开关控制 R 和 S。只要 CLK 信号是 1,R 和 S 就可以设置输出 Q。而当 CLK 信号是 0 的时候,无论 R 和 S 怎么设置,输出信号 Q 是不变的。这样,这个电路就成了我们最常用的 D 型触发器。用来控制 R 和 S 这两个开关的信号呢,我们视作一个输入的数据信号 D,也就是 Data,这就是 D 型触发器的由来。
...
July 30, 2022
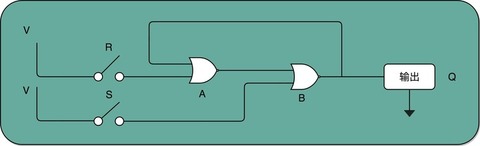
下面这个 RS 触发器电路由两个或非门电路组成。在图里面,把它标成了 A 和 B。
 或非门的真值表
NOR 0 1
0 1 0
1 0 0
或非门的真值表
NOR 0 1
0 1 0
1 0 0
这样一个电路,我们称之为触发器(Flip-Flop)。接通开关 R,输出变为 1,即使断开开关,输出还是 1 不变。接通开关 S,输出变为 0,即使断开开关,输出也还是 0。也就是,当两个开关都断开的时候,最终的输出结果,取决于之前动作的输出结果,这个也就是我们说的记忆功能。
...