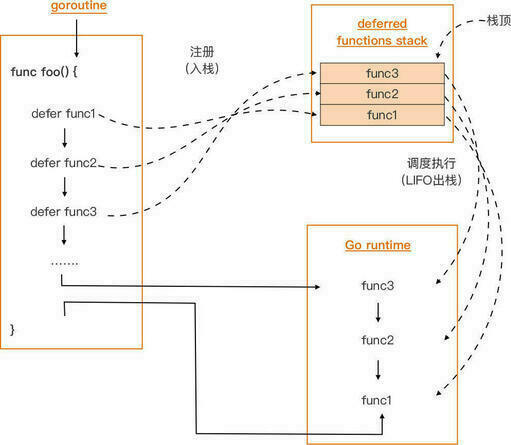
转移(Evacuation) #
G1 的垃圾清理是通过把活跃的对象,从一个 Region 拷贝到另一个空白 Region,这个空白 Region 隶属于 Survivor 空间。这个过程在 G1 GC 中被命名为转移(Evacuation)。它和基于 copy 的 GC 的最大区别是:它可以充分利用 concurrent mark 的结果快速定位到哪些对象需要被拷贝。
接下来让我们通过一个例子,来看看 G1 Evacuation 的具体过程吧。
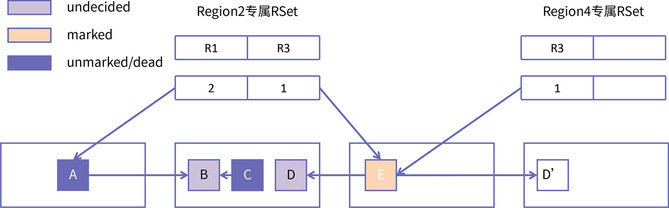 在上图中,Region2 是一个待回收的 Region,隶属于 CSet。在它的专属 RSet
中记录了 Region1 的第二个 card 和 Region3 的第一个 card,说明 Region1
和 Region3 有对 Region2 的对象引用,Region4 是一个被选为 Survivor 的空白 Region。
在上图中,Region2 是一个待回收的 Region,隶属于 CSet。在它的专属 RSet
中记录了 Region1 的第二个 card 和 Region3 的第一个 card,说明 Region1
和 Region3 有对 Region2 的对象引用,Region4 是一个被选为 Survivor 的空白 Region。
假如 Region1 和 Region3 都经过了并发标记,识别出 A 对象是垃圾对象,而 E 对象是活跃对象。那么,我们就可以从活跃对象 E 开始进行遍历。注意,这一次遍历的目标是把 Region2 中的对象搬移到 Region4。
Region1 中的 A 是垃圾对象,这在并发标记阶段就已经发现了,所以在转移阶段就不会再起作用了。进而,Region2 中的 B、C 也不会被标记到,最终只有对象 D 被拷贝到了 Region4,与此同时,原始 Region2 的 RSet 也会被维护到 Region4。
... 这是初始时状态,prevTAMS,nextTAMS 和 top 指针都指向一个分区的开始位置。
这是初始时状态,prevTAMS,nextTAMS 和 top 指针都指向一个分区的开始位置。
 随着业务线程的执行,top 指针不断向后移动。并发标记开始时,nextTAMS 记录下当前的 top 指针,并且针对 nextTAMS 之前的对象进行活跃性扫描,扫描的结果就存放在 nextBitMap 中。
随着业务线程的执行,top 指针不断向后移动。并发标记开始时,nextTAMS 记录下当前的 top 指针,并且针对 nextTAMS 之前的对象进行活跃性扫描,扫描的结果就存放在 nextBitMap 中。 当并发标记结束以后,nextTAMS 的值就记录在 prevTAMS 中,并且 nextBitMap
也赋值给 prevBitMap。
当并发标记结束以后,nextTAMS 的值就记录在 prevTAMS 中,并且 nextBitMap
也赋值给 prevBitMap。
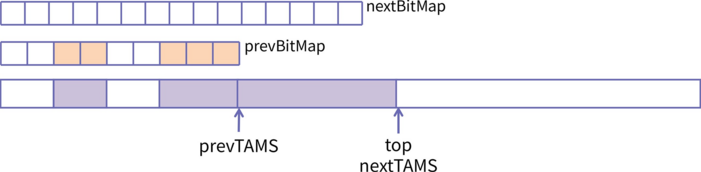 如果此时发生了 Evacuation,则 prevBitMap 已经可用了。如果没有发生
Evacuation,那么 nextBitMap 就会清空,为下一轮并发标记做准备。这样就可以保证,在任意时刻开启 Evacuation 的话,prevBitMap总是可用的。
如果此时发生了 Evacuation,则 prevBitMap 已经可用了。如果没有发生
Evacuation,那么 nextBitMap 就会清空,为下一轮并发标记做准备。这样就可以保证,在任意时刻开启 Evacuation 的话,prevBitMap总是可用的。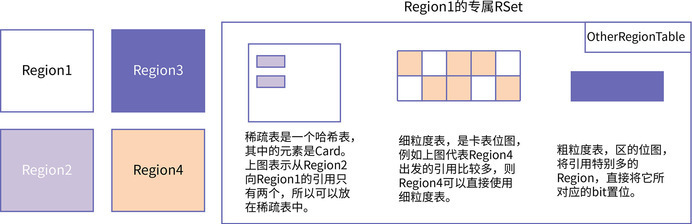
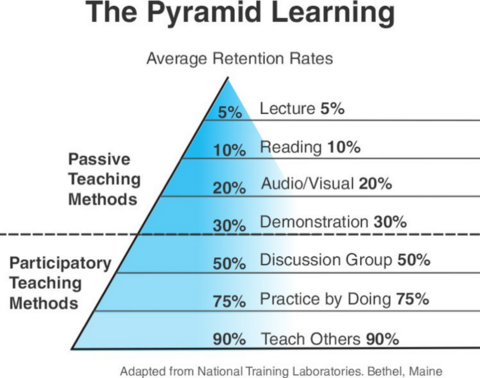 人的学习分为「被动学习」和「主动学习」两个层次。
人的学习分为「被动学习」和「主动学习」两个层次。