
方法集合决定接口实现 #
我们可以使用 dumpMethodSet 工具函数,输出下面例子中 pt 与 t 各自所属类型的方法集合:
type Interface interface {
M1()
M2()
}
type T struct{}
func (t T) M1() {}
func (t *T) M2() {}
func main() {
var t T
var pt *T
var i Interface
i = pt //正确
i = t //报错,显示T未实现M2方法
dumpMethodSet(t)
dumpMethodSet(pt)
}
运行上述代码,我们得到如下结果:
main.T's method set:
- M1
*main.T's method set:
- M1
- M2
T 类型的方法集合中只包含 M1,没有 Interface 类型方法集合中的 M2 方法,这就是 Go 编译器认为变量 t 不能赋值给 Interface 类型变量的原因。
在输出的结果中,我们还看到 *T 类型的方法集合除了包含它自身定义的 M2 方法外,还包含了 T 类型定义的 M1 方法,*T 的方法集合与 Interface 接口类型的方法集合是一样的,因此 pt 可以被赋值给 Interface 接口类型的变量 i。
...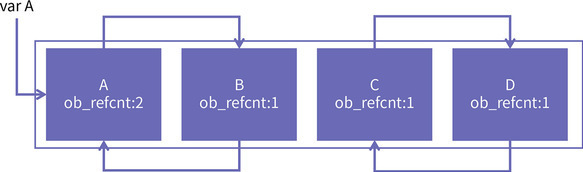 Python 为了解决这个问题,在虚拟机中引入了一个双向链表,把所有对象都放到这个链表里。Python 的每个对象头上都有一个名为 PyGC_Head 的结构:
Python 为了解决这个问题,在虚拟机中引入了一个双向链表,把所有对象都放到这个链表里。Python 的每个对象头上都有一个名为 PyGC_Head 的结构: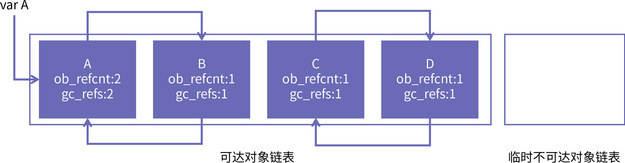
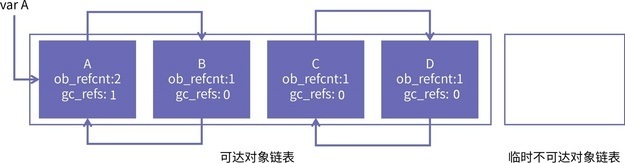
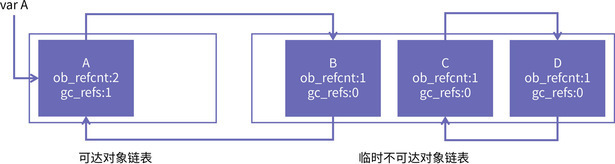
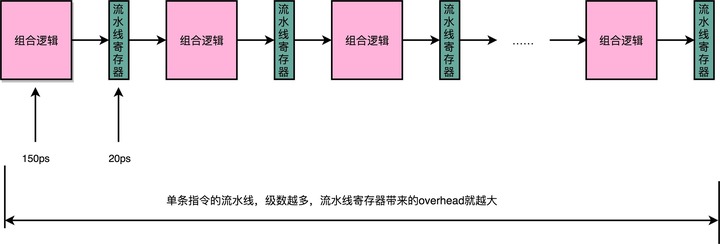 但是,如果不断加深流水线,这些操作占整个指令的执行时间的比例就会不断增加。
但是,如果不断加深流水线,这些操作占整个指令的执行时间的比例就会不断增加。