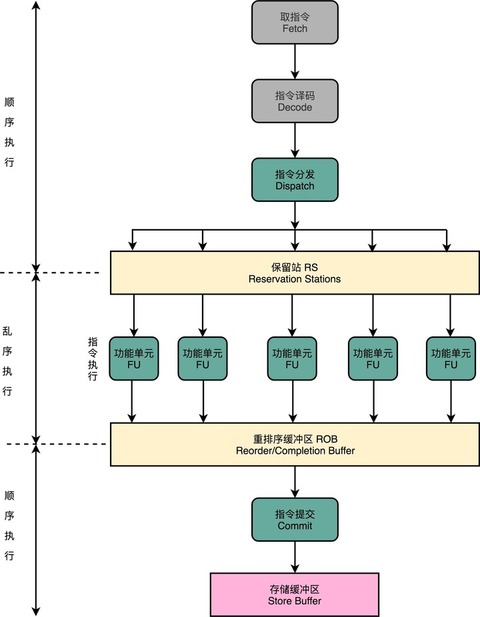
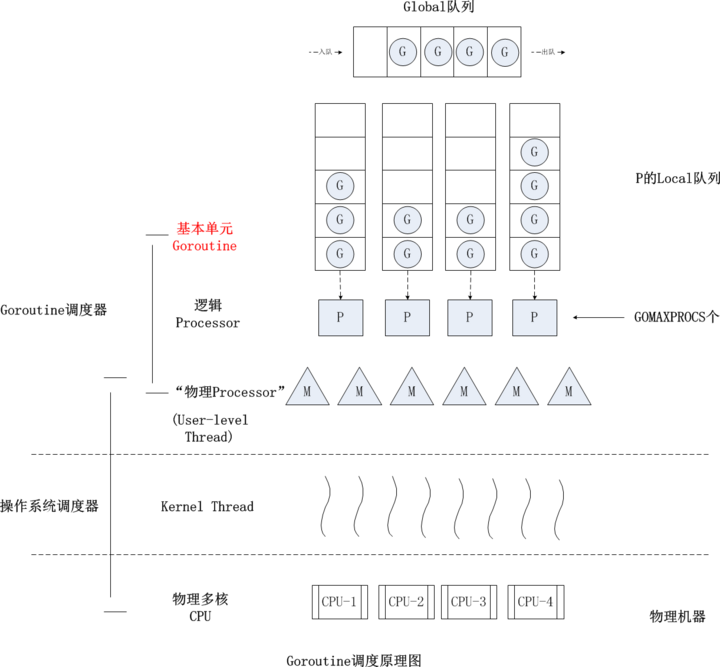
Content #
超前不一定是坏事,有时候因为自己走在别人前面,就有了明显的竞争优势。但是太超前就不一定是好事了,因为这种公司不一定能够有时间等到概念成熟的时候,可能在这之前就破产了。
理念太超前到底好不好?这是一个非常不好回答的问题。我这里先来列举一些具体的例子吧。
2000 年前后,Sun 公司提出了现在大家耳熟能详的云计算的概念。Sun 公司觉得将来的计算资源就应该和水电一样,开起来就能用,用多少付多少钱。这个想法可能你今天听起来并不陌生,但是在 2000 年的时候,很多公司、很多人都在嘲笑 Sun。
当然,在那个时候,硬件的发展不足以支撑这个想法的实现。互联网在 2000 年的下载速度,连看个高清电影点播都是很困难的,又何谈如水、如电那样让人随便用,并按使用付费呢?
后来 Sun 公司当然是没有成为改变世界的云计算的大厂商。而 2006 年开始提供云计算服务的亚马逊成了全球最大的云计算厂商,2009 年开始大张旗鼓宣传云计算的阿里巴巴成了中国最大的云计算厂商。
再看另外一个例子:Salesforce。Salesforce 成立的 1999 年,创始人贝尼奥夫就觉得买软件和硬件的方式已经过时了,到了软件开发厂商消灭掉软件、改为提供服务的时候了。
这个想法是不是很超前?当然是的。因为大概是到了 2015 年以后大家才开始在普遍的层面上认可和接受了这个方向。即使这样,不得不说,现在依然还是软件和云计算并存的局面。一切都上云,所有的软件都基于软件服务,这恐怕还得等很久。
Salesforce 成立于 1999 年,和 Sun 公司不一样的是,它的创始人在提出一个超前的概念之后,不仅仅让这个公司存活了下来,而且随着人们对 SaaS 以及云计算的认可越来越深,公司逐渐成长起来,业绩越做越大。Salesforce 并没有因为概念超前而倒在沙滩上。因此,“概念超前,公司要死”这个说法也不完全是正确的。
那么 Sun 和 Salesforce 的区别在于什么地方呢?
我觉得有两个非常不同的区别。
第一个是,这个超前的概念到底是基于什么层面的超前。 具体一点来说,如果一个超前的概念是本质性的,需要延生到整个领域的方方面面的,比如操作系统的改变、硬件层面的改变。这种层面的改变要实施起来,无论财力、人力、物力以及投资的持续性都是非常高的,并非一般企业就可以做下来的。
但如果说这个超前的概念是针对某一个特定领域,并且这个领域又相对比较狭窄,领域内有足够多“愿意吃螃蟹的人”。那么这种概念的超前就要好很多。
第二个是,提出这个概念的人或者公司到底是以一种什么样的态度去对待这个概念。 简单来说,是踏踏实实一点一点地把事情做出来呢?还是“放一个大炮”,除了让大家觉得很牛或者很不切实际之外,就没有其他有价值的东西了呢?
Sun 公司并未在其提出的超前概念上投入足够多的研发,更不用提坚持下去了。而 Salesforce 则很不一样。Salesforce 选择了某一个特定的领域,深耕下去,把产品做出来,把市场打出去,吸引一部分用户来用。这样的话,即使作为一个非常超前的概念,但是在具体领域、具体问题上,这种超前的距离感已经被现实存在的产品拉近了。
在我看来,“只是说说”与“脚踏实地去一点一点地解决问题”有非常大的差别。很多时候,公司可以提出超前的概念,可却不一定愿意投入资源去付诸实施。但是从现实来讲,任何产业都是“读万卷书,行万里路”的。倘若一个公司不愿意做实际的事情的话,那么再多超前的概念也没意义。
而一个超前的概念到底能不能够帮助一个公司活下来,还有另外两个方面的考量。
第一个方面是,概念到底有多超前。
假设我们知道 100 年后人工智能会全面接管人类的日常生产生活,那么是不是今天我们提出“100 年以后人工智能会全面接管人类的日常生产生活”就是一个很好的超前概念呢?我觉得不是。因为这个概念太超前,没有任何的可执行性,对当下的实际没有任何改变。
如果我们今天就创建一个公司,把这个超前的概念付诸实施,最后的结果又会不会是技术还没有准备好,企业很快就倒塌了呢?我觉得这是必然的。因为现在发展的技术 100 年以后才能用,谁也不能保证有足够多的钱烧到技术可以盈利的那一天。
第二个方面是,一个企业能否运用这个超前的概念在一定的领域范围内具备赢利的能力。
这个之于不同公司,适用程度会不同。其中对创业公司尤其重要。大公司,比如亚马逊和阿里巴巴,都是长年累月地从其他行业里面赚钱来补贴云计算,这才有足够的钱让云计算持续烧下去,烧到赚钱。
而小企业不可能这样搞。这样搞的小企业,投资人早就要疯掉了。所以对于小企业来说,一个超前的概念,不但需要在特定的领域里面可以落实下去,而且还要在那个领域里面能够创造利润。从这个角度来讲,能赢的概率很低。
总结一下来说,太超前了肯定不是好事情。尤其是一些涉及基础性的、宽度和深度都有可能很大的变革性的观念,这种东西太超前了往往不一定能够成功。如果可以结合具体的行业,把超前的概念在一定范围内具体实现起来,并具备赢利能力,那么这种程度的超前,很有可能是可以给公司带来一片新天地的。