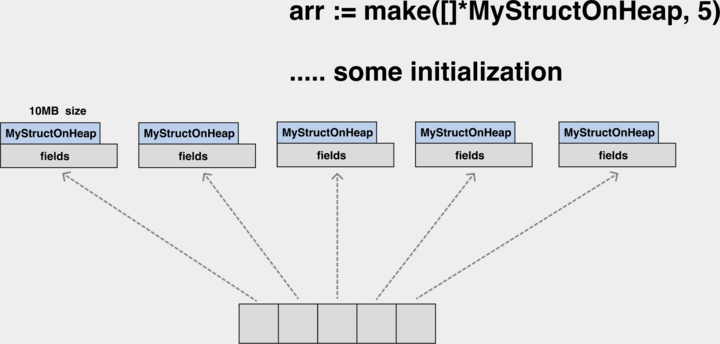
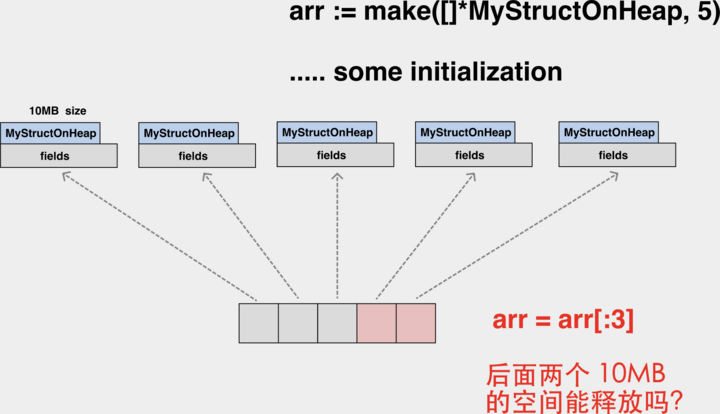
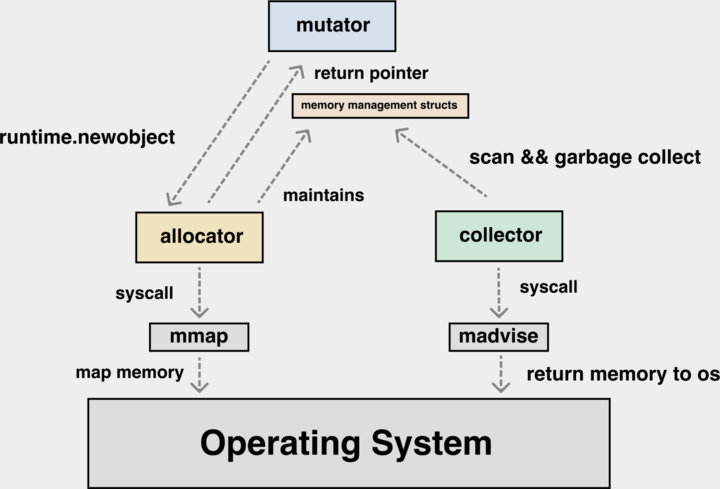
对象丢失问题 #
GC 线程 / 协程与应用线程 / 协程是并发执行的,在 GC 标记 worker 工作期间,应用还会不断地修改堆上对象的引用关系,这就可能导致对象丢失问题。下面是一个典型的应用与 GC 同时执行时,由于应用对指针的变更导致对象漏标记,从而被 GC 误回收的情况。
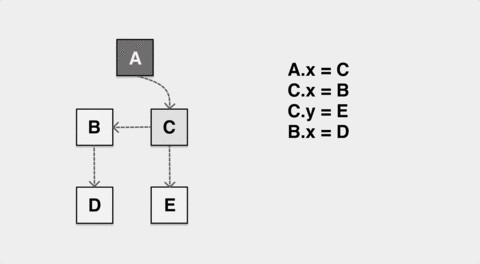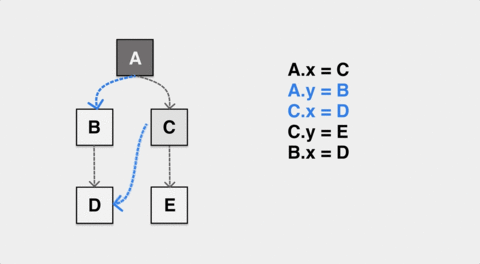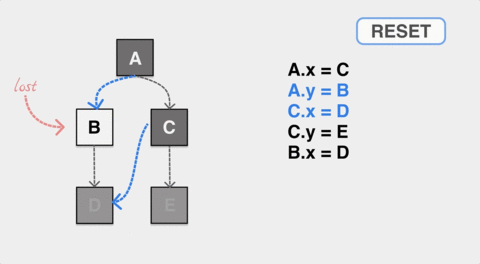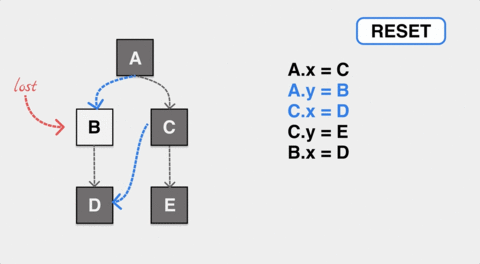
在这张图表现的 GC 标记过程中,应用动态地修改了 A 和 C 的指针,让 A 对象的内部指针指向了 B,C 的内部指针指向了 D。如果标记过程垃圾收集器无法感知到这种变化,最终 B 对象在标记完成后是白色,会被错误地认作内存垃圾被回收。
Viewpoints #
From #
Links #
什么是漏标 漏标与对象丢失问题讲的是同一件事情。