Content #
ret 和retf 经常用做call 和call far 的配对指令。ret 是近返回指令,当它执行时,处理器只做一件事,那就是从栈中弹出一个字到指令指针寄存器IP 中。
retf 是远返回指令(return far),它的工作稍微复杂一点点。当它执行时,处理器分别从栈中弹出两个字到指令指针寄存器IP 和代码段寄存器CS 中。
call 指令在执行过程调用时不影响任何标志位,ret/retf 指令对标志位也没有任何影响。
 August 22, 2022
August 22, 2022
August 22, 2022
August 22, 2022
这也属于段间调用,被调用过程位于另一个代码段内,而且,被调用过程所在的段地址和偏移地址是间接给出的。还有,这里的“16 位”同样是用来限定偏移地址的。
下面是这种调用方式的几个例子:
call far [0x2000]
call far [proc_1]
call far [bx]
call far [bx+si]
间接远调用必须使用关键字“far”,这一点务必牢记。
因为是远调用,也就是段间调用,所以,必须给出被调用过程的段地址和偏移地址。但是,段地址和偏移地址在内存中的其他位置,指令中仅仅给出的是该位置的偏移地址,需要处理器在执行指令的时候自行按图索骥,找到它们。
以上,前两条指令是等效的,不同之处仅仅在于,第一条指令直接给出的是数值,而第二条指令用的是标号。但这无关紧要,在编译后,标号也会变成数值。
下面是一个实例。假如在数据段内声明了标号proc_1 并初始化了两个字:
proc_1 dw 0x0102, 0x2000
这两个字分别是某个过程的段地址和偏移地址。按处理器的要求,偏移地址在前,段地址在后。也就是说,0x0102 是偏移地址; 0x2000 是段地址。
那么,为了调用该过程,可以在代码段内使用这条指令:
call far [proc_1]
这条指令执行过程如下:
August 22, 2022
这种调用属于段间调用,即调用另一个代码段内的过程,所以称为远调用(far call)。很容易想到,远调用既需要被调用过程所在的段地址,也需要该过程在段内的偏移地址。
“16 位”是针对偏移地址来说的,而不是限定段地址,尽管段地址事实上也是 16 位的;“直接”的意思是,段地址和偏移地址直接在call 指令中给出了。当然,这里的地址也是绝对地址。比如:
call 0x2000:0x0030
这条指令编译后的机器码为9A 30 00 00 20,0x9A 是操作码,后面跟着的两个字分别是偏移地址和段地址,按规定,偏移地址在前,段地址在后。
处理器执行过程如下:
处理器是没有脑子的。如果被调用过程位于当前代码段内,而你又用这种指令格式来调用它,那么,处理器也会不折不扣地从当前代码段“转移”到当前代码段。
August 22, 2022
近调用意味着只能调用当前代码段内的过程。指令中的操作数不是偏移量,而是被调用过程的真实偏移地址,故称为绝对地址。不过,这个偏移地址不是直接出现在指令中,而是由16 位的通用寄存器或者16 位的内存单元间接给出。比如:
call cx ;机器码为FF D1,目标偏移地址在CX中
call [0x3000] ;机器码为FF 16 00 30,从内存中取得目标偏移地址(段寄存器为DS)
call [bx] ;从ds:bx指向的内存中取得偏移地址
call [bx+si+0x02] ;基址+变址的寻址方式,其余同上
间接绝对近调用指令在执行时,处理器首先按以上的方法计算被调用过程的偏移地址,然后将指令指针寄存器IP 的当前值压栈,最后用计算出来的偏移地址取代寄存器IP 原有的内容。由于间接绝对近调用的机器指令操作数是16 位的绝对地址,因此,它可以调用当前代码段任何位置处的过程。
August 22, 2022
近调用的意思是被调用的目标过程位于当前代码段内,而非另一个不同的代码段,所以只需要得到偏移地址即可。
16 位相对近调用是三字节指令,操作码为0xE8,后跟16 位的操作数,因为是相对调用,故该操作数是当前call 指令相对于目标过程的偏移量。
计算过程如下:
举个例子:
call near proc_1
近调用的特征是在指令中使用关键字“near”。“proc_1”是程序中的一个标号。在编译阶段,编译器用标号proc_1 处的汇编地址减去本指令的汇编地址,再减去3,作为机器指令的操作数。
关键字“near”不是必需的,如果call 指令中没有提供任何关键字,则编译器认为该指令是近调用。因此,上面的指令与这条指令等效:
call proc_1
因为16 位相对近调用的操作数是两个汇编地址相减的相对量,所以,如果被调用过程在当前指令的前方,也就是说,论汇编地址,它比call 指令的要大,那么该相对量是一个正数;反之,就是一个负数。所以,它的机器指令操作数是一个16 位的有符号数。换句话说,被调用过程的首地址必须位于距离当前call 指令-32768~32767 字节的地方。
在指令执行阶段,处理器看到操作码0xE8,就知道它应当调用一个过程。其执行过程如下:
再看一个例子:
call 0x0500
在call 指令后跟一个数值,只是帮了编译器的忙,帮它省了一个转化步骤,它依然会用这个数值减去当前指令的汇编地址,来得到一个偏移量。
August 21, 2022
三个术语:“基因”、“顺反子(cistron)”、“遗传单位”分别是什么含义?彼此之间有何关联?
基因复合体只是一长串核苷酸字母,并不明显地分为一些各自独立的书页。当然蛋白质链信息的头和尾都有专门的符号,它们同蛋白质信息本身一样,都以同样 4个字母表示。这两个符号之间会有制造一种蛋白质的密码指令。如果愿意,我们可以把一个基因理解为头和尾符号之间的核苷酸字母序列和一条蛋白质链的编码。我们用“顺反子”(cistron)这个词来表示这样的单位。
顺反子是一串有固定的开始和结束标记的链条。遗传单位则是相邻密码字母的任何一个序列,它可以是顺反子的一部分,也可以是多个顺反子的组合。所谓的基因,指代一个遗传单位,这个单位足够的小,小到可以延续许多代,而且能以许多拷贝的形式存在。一个顺反子有时可称为基因,但如果有12个顺反子在一条染色体上结合得非常紧密,那么这12个顺反子也可称为基因。
基因在相当大程度上是那么不可再分的颗粒,它从祖父母一直传到子孙辈,而不与其他基因相混合。基因是不杇的,活了100万年的基因与只活了100年的基因同样“年轻”。
August 21, 2022
SACK 也就是选择性确认(Selective Acknowledgement)。其实跟普通的 ACK 相比呢,SACK 会把接收端收到的所有包的序列信息,都反馈给发送端。
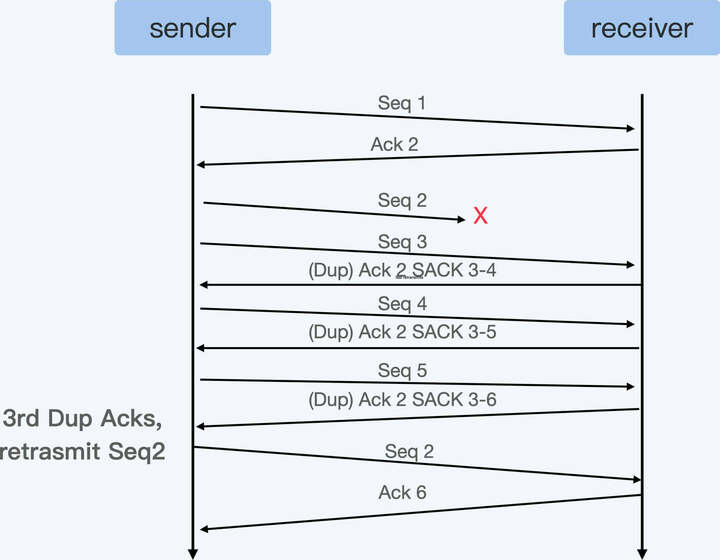
有了 SACK,对于发送端来说,在收到 SACK 之后就已经知道接收端收到了哪些数据,没有收到哪些数据。
18 | 容器网络配置(3):容器中的网络乱序包怎么这么高?
August 21, 2022
August 21, 2022
LBA28使用28个比特表示逻辑扇区号,共可以管理128GB的硬盘。
个人计算机上的主硬盘控制器被分配了8位端口,端口号从0x1f0到0x1f7。
数量写入0x1f2端口,这是个8位端口,因此每次只能读写255个扇区。
mov dx, 0x1f2
mov al, 0x1 ;1个扇区
out dx, al
如果写入的值为0,则表示读取256个扇区。
扇区读写是连续的,只要设定好第一个扇区的编号即可。28位扇区号,按从低到高,分别写入端口0x1f3, 0x1f4, 0x1f5, 0x1f6。
mov dx, 0x1f3
mov al, 0x02 ;起始扇区号为0x02
out dx, al ;7~0
inc dx
mov al, 0x00
out dx, al ;15~8
inc dx
out dx, al ;23~16
inc dx ;0x1f6
mov al, 0xe0 ;LBA模式
out dx, al
0x1f6端口的含义如下图所示:
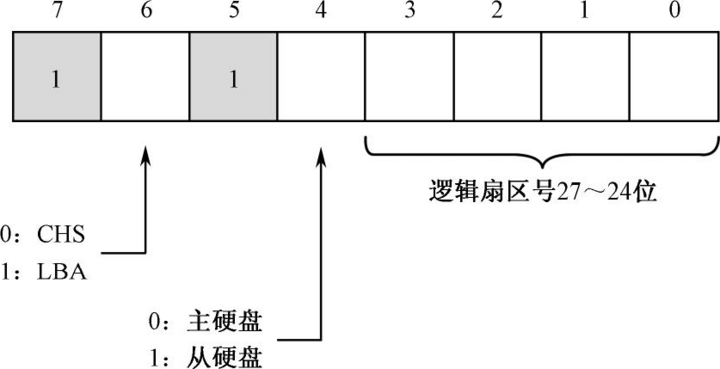 高3位是111,表示LBA模式。
高3位是111,表示LBA模式。
mov dx, 0x1f7
mov al, 0x20 ;读命令
out dx, al
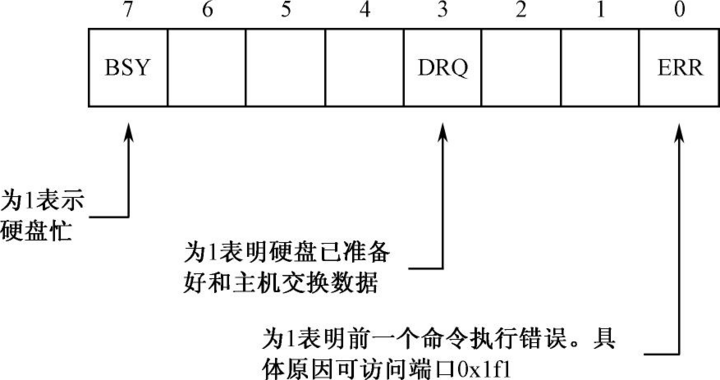
0x1f7端口即是命令端口,也是状态端口。向这个端口发送读写命令之后,硬盘就会把0x1f7端口的第7位设为1,表示自己很忙。一旦数据准备完成,第7位会被重新置0,同时,第3位会被置1,表示数据准备好了。
mov dx, 0x1f7
waits:
in al, dx
and al, 0x88
cmp al, 0x08
jnz waits
0x88的二进制为10001000,表示只取出al中的第3位与第7位。
0x1f0是16位的数据端口。下面的代码从硬盘读取256字节,放到DS指定的数据段,偏移地址由BX指定。
mov cx, 256
mov dx, 0x1f0
readw:
in ax, dx
mov [bx], ax
add bx, 2
loop readw