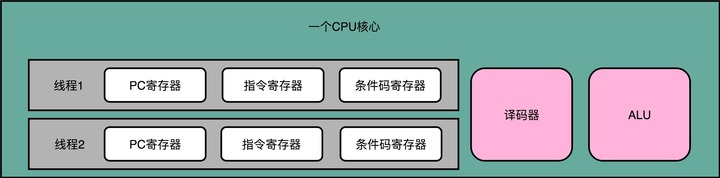
Content #
SIMD,中文叫作单指令多数据流(Single Instruction Multiple Data)。
我们先来体会一下 SIMD 的性能到底怎么样。下面是两段示例程序,一段呢,是通过循环的方式,给一个 list 里面的每一个数加 1。另一段呢,是实现相同的功能,但是直接调用 NumPy 这个库的 add 方法。在统计两段程序的性能的时候,我直接调用了 Python 里面的 timeit 的库。
$ python
>>> import numpy as np
>>> import timeit
>>> a = list(range(1000))
>>> b = np.array(range(1000))
>>> timeit.timeit("[i + 1 for i in a]", setup="from __main__ import a", number=1000000)
32.82800309999993
>>> timeit.timeit("np.add(1, b)", setup="from __main__ import np, b", number=1000000)
0.9787889999997788
>>>
从两段程序的输出结果来看,你会发现,两个功能相同的代码性能有着巨大的差异,足足差出了 30 多倍。也难怪所有用 Python 讲解数据科学的教程里,往往在一开始就告诉你不要使用循环,而要把所有的计算都向量化(Vectorize)。
有些同学可能会猜测,是不是因为 Python 是一门解释性的语言,所以这个性能差异会那么大。第一段程序的循环的每一次操作都需要 Python 解释器来执行,而第二段的函数调用是一次调用编译好的原生代码,所以才会那么快。如果你这么想,不妨试试直接用 C 语言实现一下 1000 个元素的数组里面的每个数加 1。你会发现,即使是 C 语言编译出来的代码,还是远远低于 NumPy。原因就是, NumPy 直接用到了 SIMD 指令,能够并行进行向量的操作。
...