Content #
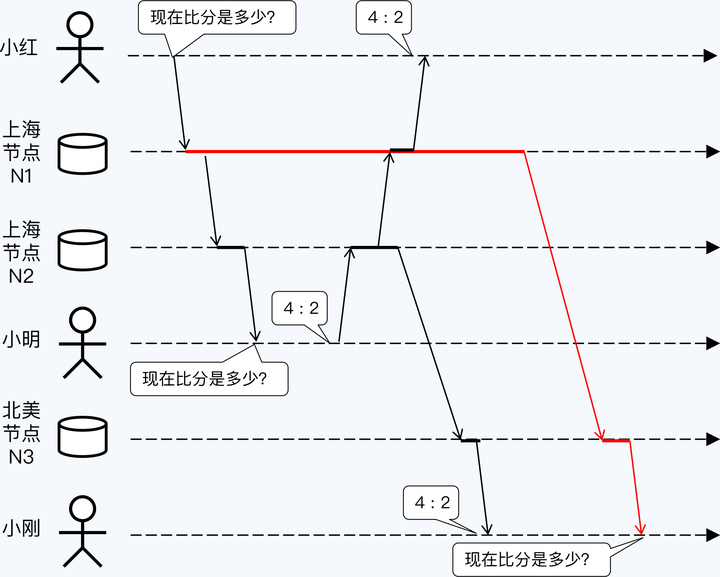
既然线性一致性不够完美,那么有没有不依赖绝对时间的方法呢?
当然是有的,这就是因果一致性(Causal Consistency)。
因果一致性的基础是偏序关系,也就是说,部分事件顺序是可以比较的。至少一个节点内部的事件是可以排序的,依靠节点的本地时钟就行了;节点间如果发生通讯,则参与通讯的两个事件也是可以排序的,接收方的事件一定晚于调用方的事件。
基于这种偏序关系,Leslie Lamport 在论文“Time, Clocks, and the Ordering of Events in a Distributed System”中提出了逻辑时钟的概念。
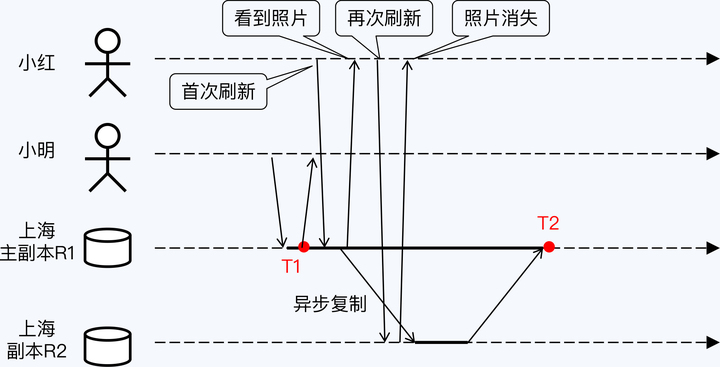
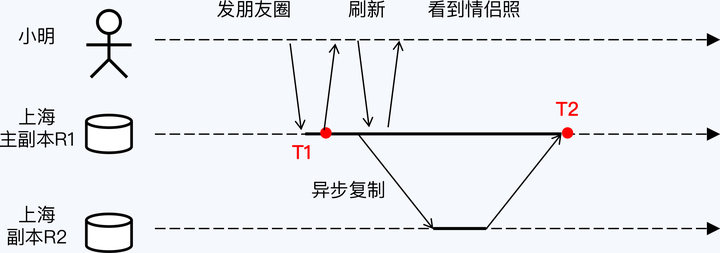
借助逻辑时钟仍然可以建立全序关系,当然这个全序关系是不够精确的。因为如果两个事件并不相关,那么逻辑时钟给出的大小关系是没有意义的。
多数观点认为,因果一致性弱于线性一致性,但在并发性能上具有优势,也足以处理多数的异常现象,所以因果一致性也在工业界得到了应用。
具体到分布式数据库领域,CockroachDB 和 YugabyteDB 都在设计中采用了逻辑混合时钟(Hybrid Logical Clocks),这个方案源自 Lamport 的逻辑时钟,也取得了不错的效果。因此,这两个产品都没有实现线性一致性,而是接近于因果一致性,其中 CockroachDB 将自己的一致性模型称为“No Stale Reads”。