Content
#
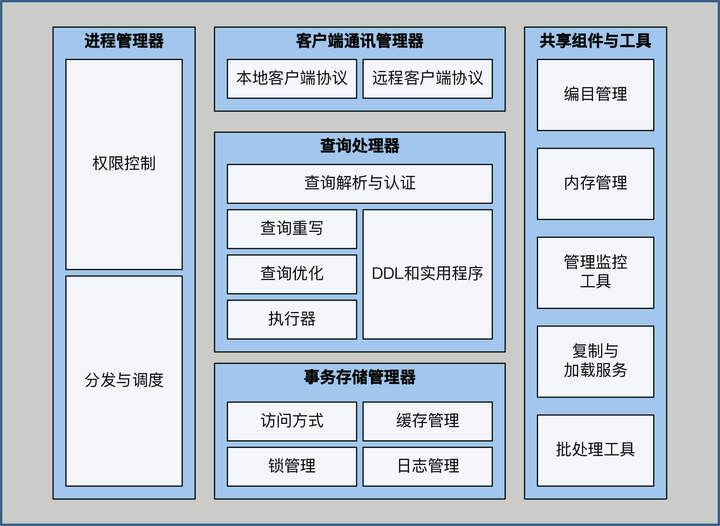
单体数据库的功能看似已经很完善了,但在面临高并发场景的时候,还是会碰到写入性能不足的问题,很难解决。因此,也就有了向分布式数据库演进的动力。要解决写入性能不足的问题,大家首先想到的,最简单直接的办法就是分库分表。
代理节点和分片信息管理
#
分库分表方案就是在多个单体数据库之前增加代理节点,本质上是增加了 SQL
路由功能。这样,代理节点首先解析客户端请求,再根据数据的分布情况,将请求转发到对应的单体数据库。
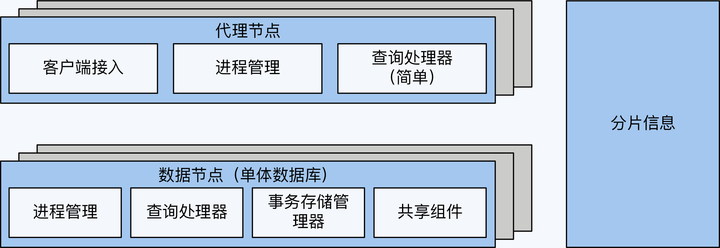
代理节点需要实现三个主要功能,它们分别是客户端接入、简单的查询处理器和进程管理中的访问控制。
另外,分库分表方案还有一个重要的功能,那就是分片信息管理,分片信息就是数据分布情况,是区别于编目数据的一种元数据。不过考虑到分片信息也存在多副本的一致性的问题,大多数情况下它会独立出来,更详细的原因我在第 7 讲中展开说明。
协调节点、跨节点查询和分布式事务组件
#
显然,如果把每一次的事务写入都限制在一个单体数据库内,业务场景就会很受局限。因此,跨库事务成为必不可少的功能,但是单体数据库是不感知这个事情的,所以我们就要在代理节点增加分布式事务组件。
同时,简单的分库分表不能满足全局性的查询需求,因为每个数据节点只能看到一部分数据,有些查询运算是无法处理的,比如排序、多表关联等。所以,代理节点要增强查询计算能力,支持跨多个单体数据库的查询。
随着分布式事务和跨节点查询等功能的加入,代理节点已经不再只是简单的路由功能,更多时候会被称为协调节点。
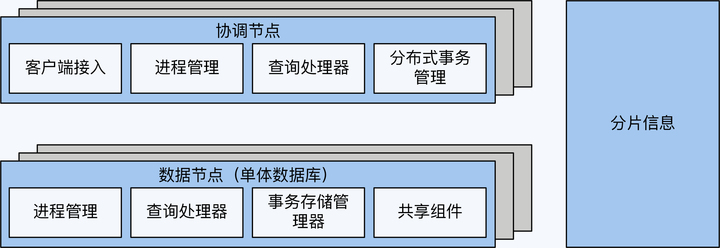
很多分库分表方案会演进到这个阶段,比如 MyCat。这时离分布式数据库还差重要的一步,就是全局时钟。全局时钟是实现数据一致性的必要条件。
全局时钟
#
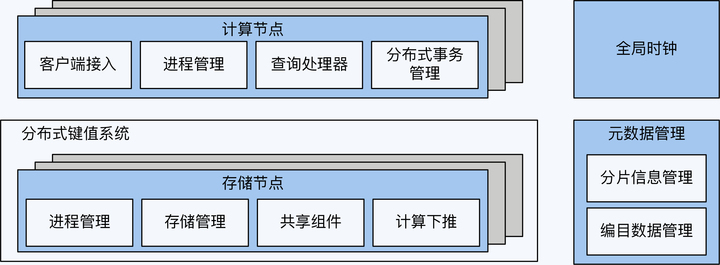
加上这最后一块拼图,PGXC 区别于单体数据库的功能也就介绍完整了,它们是分片、分布式事务、跨节点查询和全局时钟。
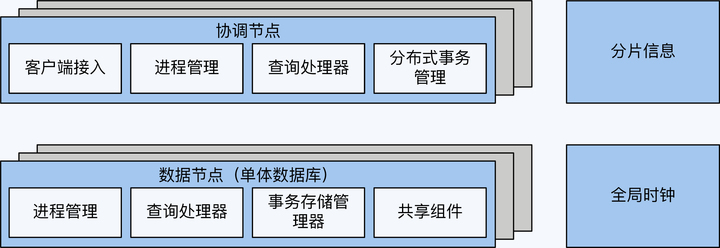
协调节点与数据节点,实现了一定程度上的计算与存储分离,这也是所有分布式数据库的一个架构基调。但是,因为 PGXC 的数据节点本身就是完整的单体数据库,所以也具备很强的计算能力。
PGXC(PostgreSQL-XC)的本意是指一种以 PostgreSQL 为内核的开源分布式数据库。因为 PostgreSQL 的影响力和开放的软件版权协议(类似 BSD),很多厂商在 PGXC 上二次开发,推出自己的产品。不过,这些改动都没有变更主体架构风格,所以我把这类产品统称为 PGXC 风格,其中包括 TBase、GuassDB 300 和
AntDB 等。当然,这里所说的 PGXC 并不限于以 PostgreSQL 为内核,那些以
MySQL 为内核的产品往往也会采用同样的架构,例如 GoldenDB,所以我把它们也归入了 PGXC 风格。
Viewpoints
#
From
#
04 | 架构风格:NewSQL和PGXC到底有啥不一样?
Links
#