Content #
图形渲染的流程 #
- 顶点处理(Vertex Processing)
- 图元处理(Primitive Processing)
- 栅格化(Rasterization)
- 片段处理(Fragment Processing)
- 像素操作(Pixel Operations)
GPU #
可编程管线(Programable Function Pipeline) 着色器(Shader) 统一着色器架构(Unified Shader Architecture)
 September 25, 2022
September 25, 2022
September 25, 2022
September 25, 2022
现在我们电脑里面显示出来的 3D 的画面,其实是通过多边形组合出来的。你可以看看下面这张图,你在玩的各种游戏,里面的人物的脸,并不是那个相机或者摄像头拍出来的,而是通过多边形建模(Polygon Modeling)创建出来的。
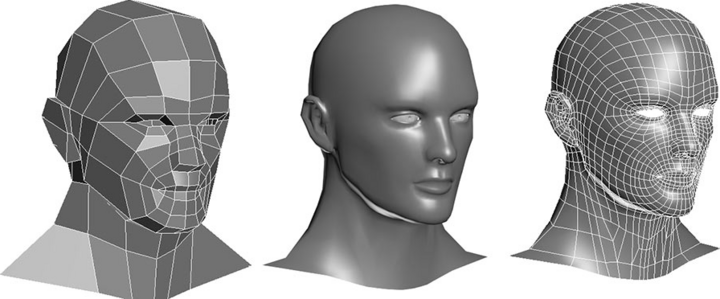
3D 游戏里的人脸,其实是用多边形建模创建出来的
而实际这些人物在画面里面的移动、动作,乃至根据光线发生的变化,都是通过计算机根据图形学的各种计算,实时渲染出来的。
这个对于图像进行实时渲染的过程,可以被分解成下面这样 5 个步骤:
经过这完整的 5 个步骤之后,我们就完成了从三维空间里的数据的渲染,变成屏幕上你可以看到的 3D 动画了。这样 5 个步骤的渲染流程呢,一般也被称之为图形流水线(Graphic Pipeline)。这个名字和 CPU 里面的流水线非常相似,都叫 Pipeline。
September 25, 2022
atomic 常常用来实现 Lock-Free 的数据结构,这次我会给你展示一个 Lock-Free queue 的实现。
Lock-Free queue 最出名的就是 Maged M. Michael 和 Michael L. Scott 1996 年发表的论文中的算法,算法比较简单,容易实现,伪代码的每一行都提供了注释,我就不在这里贴出伪代码了,因为我们使用 Go 实现这个数据结构的代码几乎和伪代码一样:
package queue
import (
"sync/atomic"
"unsafe"
)
// lock-free的queue
type LKQueue struct {
head unsafe.Pointer
tail unsafe.Pointer
}
// 通过链表实现,这个数据结构代表链表中的节点
type node struct {
value interface{}
next unsafe.Pointer
}
func NewLKQueue() *LKQueue {
n := unsafe.Pointer(&node{})
return &LKQueue{head: n, tail: n}
}
// 入队
func (q *LKQueue) Enqueue(v interface{}) {
n := &node{value: v}
for {
tail := load(&q.tail)
next := load(&tail.next)
if tail == load(&q.tail) { // 尾还是尾
if next == nil { // 还没有新数据入队
if cas(&tail.next, next, n) { //增加到队尾
cas(&q.tail, tail, n) //入队成功,移动尾巴指针
return
}
} else { // 已有新数据加到队列后面,需要移动尾指针
cas(&q.tail, tail, next)
}
}
}
}
// 出队,没有元素则返回nil
func (q *LKQueue) Dequeue() interface{} {
for {
head := load(&q.head)
tail := load(&q.tail)
next := load(&head.next)
if head == load(&q.head) { // head还是那个head
if head == tail { // head和tail一样
if next == nil { // 说明是空队列
return nil
}
// 只是尾指针还没有调整,尝试调整它指向下一个
cas(&q.tail, tail, next)
} else {
// 读取出队的数据
v := next.value
// 既然要出队了,头指针移动到下一个
if cas(&q.head, head, next) {
return v // Dequeue is done. return
}
}
}
}
}
// 将unsafe.Pointer原子加载转换成node
func load(p *unsafe.Pointer) (n *node) {
return (*node)(atomic.LoadPointer(p))
}
// 封装CAS,避免直接将*node转换成unsafe.Pointer
func cas(p *unsafe.Pointer, old, new *node) (ok bool) {
return atomic.CompareAndSwapPointer(
p, unsafe.Pointer(old), unsafe.Pointer(new))
}
我来给你介绍下这里的主要逻辑。
...
September 25, 2022
在现在的系统中,write 的地址基本上都是对齐的(aligned)。 比如,32 位的操作系统、CPU 以及编译器,write 的地址总是 4 的倍数,64 位的系统总是 8 的倍数(还记得 WaitGroup 针对 64 位系统和 32 位系统对 state1 的字段不同的处理吗)。对齐地址的写,不会导致其他人看到只写了一半的数据,因为它通过一个指令就可以实现对地址的操作。如果地址不是对齐的话,那么,处理器就需要分成两个指令去处理,如果执行了一个指令,其它人就会看到更新了一半的错误的数据,这被称做撕裂写(torn write) 。所以,你可以认为赋值操作是一个原子操作,这个“原子操作”可以认为是保证数据的完整性。
但是,对于现代的多处理多核的系统来说,由于 cache、指令重排,可见性等问题,我们对原子操作的意义有了更多的追求。在多核系统中,一个核对地址的值的更改,在更新到主内存中之前,是在多级缓存中存放的。这时,多个核看到的数据可能是不一样的,其它的核可能还没有看到更新的数据,还在使用旧的数据。
多处理器多核心系统为了处理这类问题,使用了一种叫做内存屏障(memory fence 或 memory barrier)的方式。一个写内存屏障会告诉处理器,必须要等到它管道中的未完成的操作(特别是写操作)都被刷新到内存中,再进行操作。此操作还会让相关的处理器的 CPU 缓存失效,以便让它们从主存中拉取最新的值。
atomic 包提供的方法会提供内存屏障的功能,所以,atomic 不仅仅可以保证赋值的数据完整性,还能保证数据的可见性,一旦一个核更新了该地址的值,其它处理器总是能读取到它的最新值。但是,需要注意的是,因为需要处理器之间保证数据的一致性,atomic 的操作也是会降低性能的。
12 | atomic:要保证原子操作,一定要使用这几种方法
September 25, 2022
因为不同的 CPU 架构甚至不同的版本提供的原子操作的指令是不同的,所以,要用一种编程语言实现支持不同架构的原子操作是相当有难度的。不过,还好这些都不需要你操心,因为 Go 提供了一个通用的原子操作的 API,将更底层的不同的架构下的实现封装成 atomic 包,提供了修改类型的原子操作(atomic read-modify-write,RMW)和加载存储类型的原子操作(Load 和 Store)的 API。
有的代码也会因为架构的不同而不同。有时看起来貌似一个操作是原子操作,但实际上,对于不同的架构来说,情况是不一样的。比如下面的代码的第 4 行,是将一个 64 位的值赋值给变量 i:
const x int64 = 1 + 1<<33
func main() {
var i = x
_ = i
}
如果你使用 GOARCH=386 的架构去编译这段代码,那么,第 5 行其实是被拆成了两个指令,分别操作低 32 位和高 32 位。反编译指令:
> GOARCH=386 go tool compile -N -l test.go
> GOARCH=386 go tool objdump -gnu test.o
main.go:5 0x37b 83ec08 SUBL $0x8, SP // sub $0x8,%esp
main.go:6 0x37e c7042401000000 MOVL $0x1, 0(SP) // movl $0x1,(%esp)
main.go:6 0x385 c744240402000000 MOVL $0x2, 0x4(SP) // movl $0x2,0x4(%esp)
main.go:8 0x38d 83c408 ADDL $0x8, SP // add $0x8,%esp
如果 GOARCH=amd64 的架构去编译这段代码,那么,第 5 行其中的赋值操作其实是一条指令:
...
September 25, 2022
当处理器执行任何一条改变栈段寄存器SS 的指令时,它会在下一条指令执行完期间禁止中断。
要想改变代码段和数据段,只需要改变段寄存器就可以了。但栈段不同,因为它除了有段寄存器,还有栈指针。因此,绝大多数时候,对栈的改变是分两步进行的:先改变段寄存器SS 的内容,接着又修改栈指针寄存器SP 的内容。想象一下,如果刚刚修改了段寄存器SS,在还没来得及修改SP 的情况下,就发生了中断,会出现什么后果,而且要知道,中断是需要依靠栈来工作的。
因此,处理器在设计的时候就规定,当遇到修改段寄存器SS 的指令时,在这条指令和下一条指令执行完毕期间,禁止中断,以此来保护栈。换句话说,你应该在修改段寄存器SS 的指令之后,紧跟着一条修改栈指针SP 的指令。
September 25, 2022
int3 是断点中断指令,机器指令码为CC。这条指令在调试程序的时候很有用,当程序运行不正常时,多数时候希望在某个地方设置一个检查点,也称断点,来查看寄存器、内存单元或者标志寄存器的内容,这条指令就是为这个目的而设的。
指令都是连续存放的,因此,所谓的断点,就是某条指令的起始地址。int3 是单字节指令,这是有意设计的。当需要设置断点时,可以将断点处那条指令的第 1 字节改成0xcc,原字节予以保存。当处理器执行到int3 时,即发生3 号中断,转去执行相应的中断处理程序。中断处理程序的执行也要用到各个寄存器,这会破坏它们的内容,但push 指令不会。我们可以在该程序内先压栈所有相关寄存器和内存单元,然后分别取出予以显示,它们就是中断前的现场内容。最后,再恢复那条指令的第1 字节,并修改位于栈中的返回地址,执行iret 指令。
September 25, 2022
在保护模式下,代码段是不可写入的。所谓不可写入,并非是说改变了内存的物理性质,使得内存写不进去,而是说,通过该段的描述符来访问这个区域时,处理器不允许向里面写入数据或者更改数据。但是,很多时候,又需要对代码段做一些修改。比如在调试程序时,需要加入断点指令int3。不管怎么样,如果需要访问代码段内的数据,只能重新为该段安装一个新的描述符,并将其定义为可读可写的数据段。这样,当需要修改代码段内的数据时,可以通过这个新的描述符来进行。
像这样,当两个以上的描述符都描述和指向同一个段时,把另外的描述符称为别名(alias)。注意,别名技术并非仅仅用于读写代码段,如果两个程序想共享同一个内存区域,可以分别为每个程序都创建一个描述符,而且它们都指向同一个内存段,这也是别名应用的例子。
September 25, 2022
首先,描述符的类别字段必须是有效的值,0000 是无效值的一个例子。
然后,检查描述符的类别是否和段寄存器的用途匹配。其规则如下表所示。
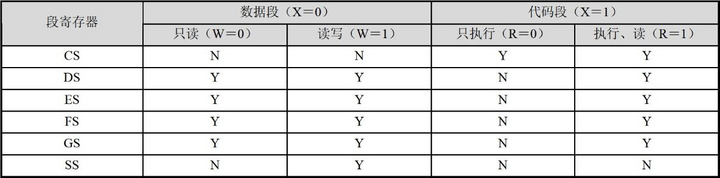 只有可以写入的数据段才能加载到SS 的选择器,CS 寄存器只允许加载代码段描述符。另外,对于DS、ES、FS 和GS 的选择器,可以向其加载数值为0 的选择子,即尽管在加载的时候不会有任何问题,但在,真正要用来访问内存时,就会导致一个异常中断。这是一个特殊的设计,处理器用它来保证系统安全。不过,对于CS 和SS的选择器来说,不允许向其传送值为0 的选择子。
只有可以写入的数据段才能加载到SS 的选择器,CS 寄存器只允许加载代码段描述符。另外,对于DS、ES、FS 和GS 的选择器,可以向其加载数值为0 的选择子,即尽管在加载的时候不会有任何问题,但在,真正要用来访问内存时,就会导致一个异常中断。这是一个特殊的设计,处理器用它来保证系统安全。不过,对于CS 和SS的选择器来说,不允许向其传送值为0 的选择子。
最后,除了按表进行段的类别检查外,还要检查描述符中的P 位。如果P=0,表明虽然描述符已被定义,但该段实际上并不存在于物理内存中。此时,处理器中止处理,引发异常中断11。一般来说,应当定义一个中断处理程序,把该描述符所对应的段从硬盘等外部存储器调入内存,然后置P 位。中断返回时,处理器将再次尝试刚才的操作。如果P=1,则处理器将描述符加载到段寄存器的描述符高速缓存器,同时置A 位(仅限于当前讨论的存储器的段描述符)。
注意,如表中所指示的那样,可读的代码段类似于ROM。可以用段超越前缀“cs:”来读其中的内容,也可以将它的描述符选择子加载到DS、ES、FS、GS 来做为数据段访问。代码段在任何时候都是不可写的。
一旦上述规则全部验证通过,处理器就将选择子加载到段寄存器的选择器。* From
September 24, 2022
事实证明,我们内心隐含的爱情观念可以增强或伤害我们之间的关系。斯派克·李(Spike W.S.Lee)和诺伯特·施瓦茨(Norbert Schwarz)比较了那些把爱视为一体的“灵魂伴侣”(“我们是为彼此而生的”,“她是我的另一半”),以及那些把爱描绘成一次旅行的人(“看我们走了多远”,“我们一起经历了所有这些事情”)。他们发现,这两种思考关系的方式会影响伴侣如何处理冲突的潜在破坏性影响。毕竟,如果两个人真的是天造地设的一对,如果他们属于“一个灵魂”,他们为什么会有任何冲突呢?如果他们真的有冲突,那一定意味着他们根本不是一个灵魂。在一项实验中,李和施瓦茨让长期交往的人完成一项知识测验,其中包括与团结或旅程有关的表述,然后回忆与恋人之间的冲突或庆祝活动,最后评估他们之间的关系。正如预测的那样,回忆冲突会让那些持一体心态的人对他们的关系感到不那么满意,但对于那些看到自己在一起旅行的人来说,冲突不会影响他们的满意度。
雷蒙德·尼(C.Raymond Knee)的一项纵向研究发现,对于那些相信浪漫命运的人来说,满足感和在一起的时间长短之间联系更强,但它也与应对压力时的逃避策略有关。“命中注定”的关系在风平浪静的时候是最幸福的,但当狂风暴雨袭来时,他们的爱情小舟却会搁浅。这些夫妻发现,当他们的伴侣不可避免地不再符合他们的理想标准时,他们很难在关系中保持满意。相比之下,那些认为爱情是随着年龄增长而增长的夫妻在应对策略上投入了更多的努力。随着时间的推移,他们会更满意——即使他们的伴侣不再满足他们最初的理想。他们期望自己的伴侣随着时间的推移而改进和变化,他们对关系衰退的暂时性有更好的理解。对于“让我们一起解决”的夫妻来说,冲突与他们对关系质量的评估没有关系;相反,他们会积极地与伴侣讨论问题,并修复彼此之间的裂痕。