Content #
在 Basic Paxos 中,有提议者(Proposer)、接受者(Acceptor)、学习者(Learner)三种角色,他们之间的关系如下:
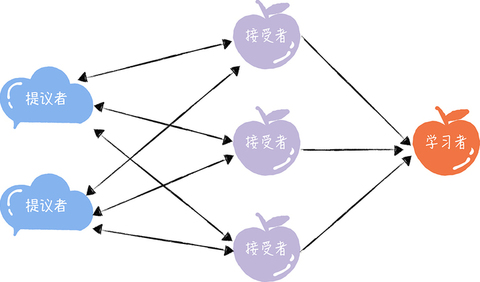
看着是不是有些复杂,其实并不难理解:
-
提议者(Proposer):提议一个值,用于投票表决。为了方便演示,你可以把图 1 中的客户端 1 和 2 看作是提议者。但在绝大多数场景中,集群中收到客户端请求的节点,才是提议者(图 1 这个架构,是为了方便演示算法原理)。这样做的好处是,对业务代码没有入侵性,也就是说,我们不需要在业务代码中实现算法逻辑,就可以像使用数据库一样访问后端的数据。
-
接受者(Acceptor):对每个提议的值进行投票,并存储接受的值,比如 A、 B、C 三个节点。 一般来说,集群中的所有节点都在扮演接受者的角色,参与共识协商,并接受和存储数据。
讲到这儿,你可能会有疑惑:前面不是说接收客户端请求的节点是提议者吗?这里怎么又是接受者呢?这是因为一个节点(或进程)可以身兼多个角色。想象一下,一个 3 节点的集群,1 个节点收到了请求,那么该节点将作为提议者发起二阶段提交,然后这个节点和另外 2 个节点一起作为接受者进行共识协商,就像下图的样子:
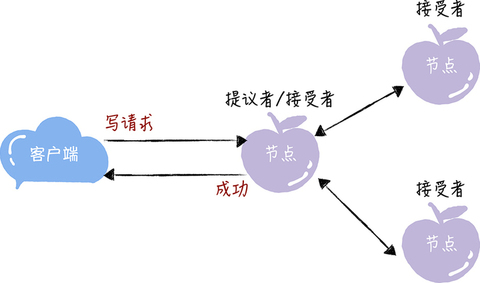
- 学习者(Learner):被告知投票的结果,接受达成共识的值,存储保存,不参与投票的过程。一般来说,学习者是数据备份节点,比如“Master-Slave”模型中的 Slave,被动地接受数据,容灾备份。
其实,这三种角色,在本质上代表的是三种功能:
-
提议者代表的是接入和协调功能,收到客户端请求后,发起二阶段提交,进行共识协商;
-
接受者代表投票协商和存储数据,对提议的值进行投票,并接受达成共识的值,存储保存;
-
学习者代表存储数据,不参与共识协商,只接受达成共识的值,存储保存。
因为一个完整的算法过程是由这三种角色对应的功能组成的,所以理解这三种角色,是你理解 Basic Paxos 如何就提议的值达成共识的基础。
Viewpoints #
From #
05 | Paxos算法(一):如何在多个节点间确定某变量的值?