
精力 #
伊万·伦德尔的“战前准备程序” 伦德尔的良好习惯 先行后思 将时间和行为精准化和具体化 改变最好由浅入深 四条关键的精力管理法则 四种精力来源
GTD #
GTD概要 等待清单与下一步行动清单 达芬奇定期放下工作 以GTD来应对蔡格尼克效应 GTD方法的三个主要目的 帕金森定律与蔡格尼克效应
问题 #
沟通 #
Misc #
腹部发声法 主持人如何处理别人的指责 创造力需要的两种能力 怀特海眼中的文明进步 你必须爱上失败 诱导性提问
阅读 #
思辩 #
反脆弱 #
清单革命 #
复杂环境中专家需要应用的两大困难 简单问题、复杂问题和极端复杂的问题 两套清单应对极端复杂的问题 不能有一粒棕色巧克力豆 发现霍乱疫情的爆发源头 降低卡拉奇贫民窟儿童过高的夭折率 介绍自己的名字 精确、高效、切中要害 清单编制6大要点 操作确认和边读边做 新知识系统地转变为清单 投资家的清单
和这个世界讲讲道理 #
刺猬和狐狸 棘手问题(Wicked Problem) 应对棘手问题的建议 好歌想要流行需要很大的运气 把成长归结于吃苦是一种归因谬误 公平世界假设的三个害处 关系成功与否的三个影响因素 构建更重要 混杂信息(Muddled Information)与考试刷分 对指标的算法保密 坎贝尔定律(Campbell’s law) 最简单经济学的五个智慧 市场中过度保护某一群体是错误的 complex是比complicated更高级的复杂 任何大型社会项目的任何效果评估的预期值等于0 不断地变动自己的世界观 道德判断是直觉式的、感性的快速判断 曲木(crooked timber)传统 资本主义的本质是关于信息的 供给创造新的需求 三种面对市场的态度和三种教育境界 人类发展的两个制胜法宝 好社会的八大特征 趋同进化(convergent evolution) 进化不是完全随机的 政治格局中的三围 五个通用的权力规则 安理会效应 收集易拉罐的遗传算法 中国模式的巨大成功是因为起点低 先发表后过滤 红皇后假说(Red Queen Hypothesis) 四种事物的年龄和存活关系 七十年的坎 内卷就是向内演化(Involution) 中国高考的确是内卷 内卷与内耗 辉格史观 排位稀缺 三种排位稀缺 帝国的暴力只能来自边缘地带
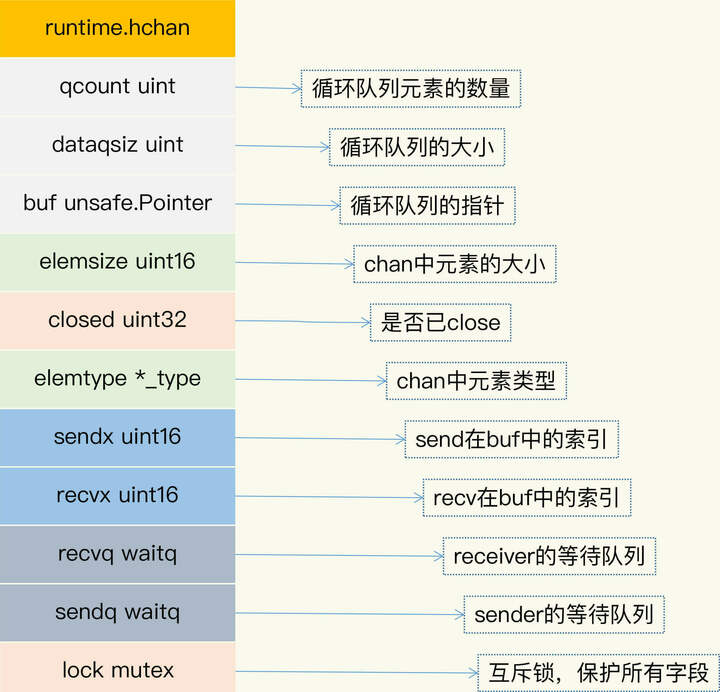
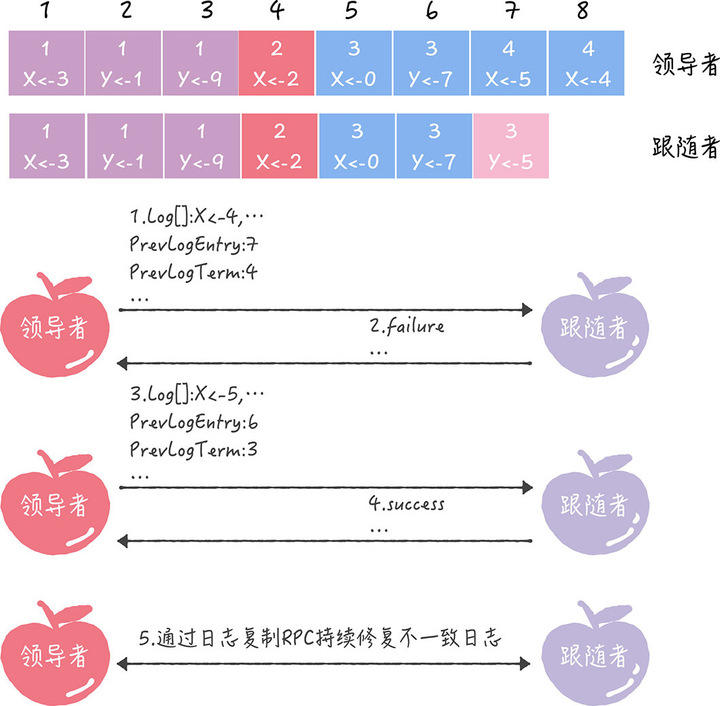 标注在箭头上方。
标注在箭头上方。