Content #
当然,固定型思维模式者也在书里读到过这样的话:成功意味着做到最好的自己,而不是要强于他人;失败是一次机会,而不是死刑;努力是通往成功的关键。但是他们无法将这些话化为实际行动,因为他们的基本思维模式——认为个人能力不可改变的这种信念——给了他们完全不同的观点:成功仅仅意味着比其他人更有天赋,失败确实会对你做出评判,而努力是那些无法依靠天赋成功的人才需要的。
From #
终身成长
 October 6, 2022
October 6, 2022
October 6, 2022
October 6, 2022
思维模式改变了失败的意义
马丁夫妇非常爱他们3岁的儿子罗伯特,经常吹嘘他有多非凡。从来没有哪个孩子能像他们的孩子一样聪明,一样富有创造性。后来,罗伯特做了一件不能被原谅的事——他没有考进纽约排名第一的幼儿园。在这之后,马丁夫妇就对他很冷淡。他们不再用以前的方式和他说话,也不像以前那么以他为豪,表达对他的爱。他不再是他们才华横溢的小罗伯特,而变成了一个让自己丢脸并让家人蒙羞的人。在如此稚嫩的年纪,他已经成了一个失败者。
就像《纽约时报》上的一篇文章指出的,失败从一种行为(我失败了)转变为一种身份(我是一个失败者),这对那些固定型思维模式者来说尤其如此。
当我还是一个孩子的时候,我也同样害怕罗伯特的这种命运降临到我头上。六年级的时候,我是学校里拼写最厉害的孩子,校长想让我去参加市级比赛,但是我拒绝了。九年级的时候,我的法语很好,我的老师想让我去参加一个市级比赛,我再一次拒绝了。为什么我要冒这个从成功到失败的风险?从一个胜利者变成一个失败者?
终身成长
October 6, 2022
October 6, 2022
当固定型思维模式者选择成功而不是成长的时候,他们到底想证明什么?他们想要证明自己很特别,甚至是高人一等。
当我问他们“你们什么时候感到自己很聪明”时,他们当中的很多人都说,在他们感到特殊的时候,或者感到自己和别人不一样而且比别人更强的时候。
在发现思维模式并了解其运作方式之前,我也和他们一样,认为自己比别人更有天赋,正因为这样,我甚至认为自己比其他人更有价值。对我来说最可怕的想法,让我几乎不敢想象的,就是我可能成为一个普通人。生活中的每一个时刻,别人的每一个眼神对我来说都意义非凡——它们被登记在我的智力记分卡、吸引力记分卡以及受欢迎程度记分卡上。如果一天过得顺利,我可以尽情沉浸在我的高分记录中。
总的来说,相信人的能力固定不变的那些人急切盼望成功,而他们在成功后感到的不仅是自豪,他们会产生一种优越感,因为成功意味着他们固定不变的个人能力比其他人要强。
然而,在固定型思维模式这种自尊心的背后潜藏着一个简单的问题:如果成功后你会变成一个重要人物,那么当你不成功的时候,你又是什么呢?
终身成长
October 6, 2022
October 6, 2022
October 6, 2022
编译器在编译源代码时,会为无法在当前编译单元内找到定义的符号生成一个特定的符号表条目,同时把“为该符号寻找定义”这个重任交给链接器。而链接器在随后进行符号解析时,便会在包含有全部符号信息的全局符号表中进行搜索。
如果链接器在这个过程中找到了符号的多个定义,它便会按照一定的规则来进行解析。编译器在编译源代码时,会为每一个全局符号指定对应的“强弱”信息,并同时将其隐含地编码在符号对应的符号表条目中。通常来说,函数和已初始化的全局变量为强符号,而未初始化的全局变量则是弱符号。而链接器对符号定义的选择会根据如下规则进行:
符号之所以会有强弱之分,主要是为了做到这一点:当不确定某个符号是否被用户显式定义的情况下,链接器仍然可以选择使用对应的弱类型符号版本来编译程序。这种能力通常被用在各类框架中,以便为某类程序编译所依赖的代码部分提供默认实现。除此之外,在模块化的代码调试场景中(比如单元测试中的桩代码),当某个待测试模块的依赖模块还没有被实现时,链接器可以选用标记为弱类型的默认版本来编译程序。
October 6, 2022
October 6, 2022
哈希算法有个明显的缺点:当需要变更集群数时(比如从 2 个集群扩展为 3 个集群),这时大部分的数据都需要迁移,重新映射,数据的迁移成本是非常高的。
以增加节点和移除节点为例,具体说一说一致哈希是如何避免上面的问题的。假设,现在有一个节点故障了(比如节点 C):
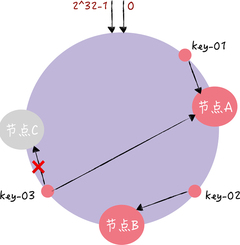
key-01 和 key-02 不会受到影响,只有 key-03 的寻址被重定位到 A。一般来说,在一致哈希算法中,如果某个节点宕机不可用了,那么受影响的数据仅仅是,会寻址到此节点和前一节点之间的数据。比如当节点 C 宕机了,受影响的数据是会寻址到节点 B 和节点 C 之间的数据(例如 key-03),寻址到其他哈希环空间的数据(例如 key-01),不会受到影响。
那如果此时集群不能满足业务的需求,需要扩容一个节点(也就是增加一个节点,比如 D):
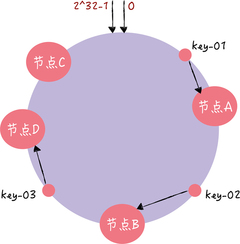
key-01、key-02 不受影响,只有 key-03 的寻址被重定位到新节点 D。一般而言,在一致哈希算法中,如果增加一个节点,受影响的数据仅仅是,会寻址到新节点和前一节点之间的数据,其它数据也不会受到影响。
让我们一起来看一个例子。使用一致哈希的话,对于 1000 万 key 的 3 节点 KV 存储,如果我们增加 1 个节点,变为 4 节点集群,只需要迁移 24.3% 的数据。
使用了一致哈希后,我们需要迁移的数据量仅为使用哈希算法时的三分之一,大大提升了效率。
总的来说,使用了一致哈希算法后,扩容或缩容的时候,都只需要重定位环空间中的一小部分数据。也就是说,一致哈希算法具有较好的容错性和可扩展性。
10 | 一致哈希算法:如何分群,突破集群的“领导者”限制?
October 6, 2022
一致哈希算法也用了取模运算,但与哈希算法不同的是,哈希算法是对节点的数量进行取模运算,而一致哈希算法是对 2^32 进行取模运算。你可以想象下,一致哈希算法,将整个哈希值空间组织成一个虚拟的圆环,也就是哈希环:

可以看到,哈希环的空间是按顺时针方向组织的,圆环的正上方的点代表 0,0 点右侧的第一个点代表 1,以此类推,2、3、4、5、6……直到 2^32-1,也就是说 0 点左侧的第一个点代表 2^32-1。
在一致哈希中,你可以通过执行哈希算法(为了演示方便,假设哈希算法函数为“c-hash()”),将节点映射到哈希环上,比如选择节点的主机名作为参数执行 c-hash(),那么每个节点就能确定其在哈希环上的位置了:
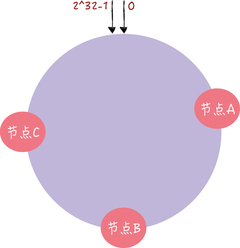
当需要对指定 key 的值进行读写的时候,你可以通过下面 2 步进行寻址:
假设 key-01、key-02、key-03 三个 key,经过哈希算法 c-hash() 计算后,在哈希环上的位置就像图 6 的样子:
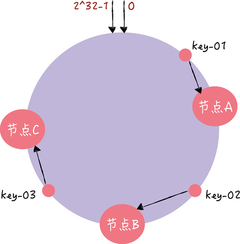
那么根据一致哈希算法,key-01 将寻址到节点 A,key-02 将寻址到节点 B, key-03 将寻址到节点 C。
10 | 一致哈希算法:如何分群,突破集群的“领导者”限制?