Content
#
set_up_gdt_descriptor: ;在GDT内安装一个新的描述符
;输入:EDX:EAX=描述符
;输出:CX=描述符的选择子
push eax
push ebx
push edx
push ds
push es
mov ebx,core_data_seg_sel ;切换到核心数据段
mov ds,ebx
sgdt [pgdt] ;以便开始处理GDT
mov ebx,mem_0_4_gb_seg_sel ;整个0-4GB内存的段的选择子
mov es,ebx ;让ES指向4GB内存段以操作全局描述符表
;计算描述符安装地址。
;1. 先得到描述符表的界限值,将它加1,得到描述符总字节数。
;2. 该总字节数即为新描述符在GDT内的偏移量。
;3. 用GDT的线性地址加上这个偏移量,就是用于安装新描述符的线性地址。
movzx ebx,word [pgdt] ;GDT界限
inc bx ;GDT总字节数,也是下一个描述符偏移#
add ebx,[pgdt+2] ;下一个描述符的线性地址
;访问ES指向的4GB内存段,将EDX:EAX中的64位段描述符写入EBX指向的偏移处
mov [es:ebx],eax
mov [es:ebx+4],edx
add word [pgdt],8 ;增加一个描述符的大小
lgdt [pgdt] ;对GDT的更改生效
;根据GDT新界限值,来生成相应的段选择子。
;界限值会比GDT总字节数小1,因此界限除以8(丢掉余数7)后的商即为描述符索引号。
mov ax,[pgdt] ;得到GDT界限值
xor dx,dx
mov bx,8
div bx ;除以8,去掉余数
mov cx,ax
shl cx,3 ;左移3次,留出TI位和RPL位
pop es
pop ds
pop edx
pop ebx
pop eax
retf
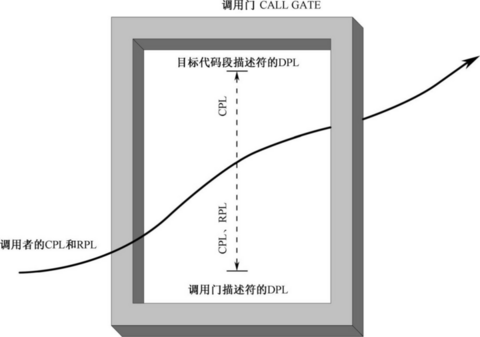
如果这是启动计算机以来,第一次在GDT 中安装描述符,两种写法会有区别。
在初始状态下,也就是计算机启动之后,这时还没有使用GDT,GDTR 寄存器中的基地址为0x00000000,界限为0xFFFF。
当GDTR 寄存器的界限部分是0xFFFF 时,表明GDT 中还没有描述符。因此,将此值加1,结果是0x10000,由于该寄存器的界限部分只有16 位,所以只能容纳16
位的结果,即0x0000,这就是第一个描述符在表内的偏移量。
...