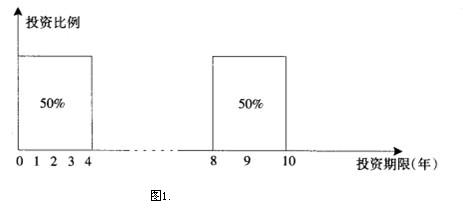
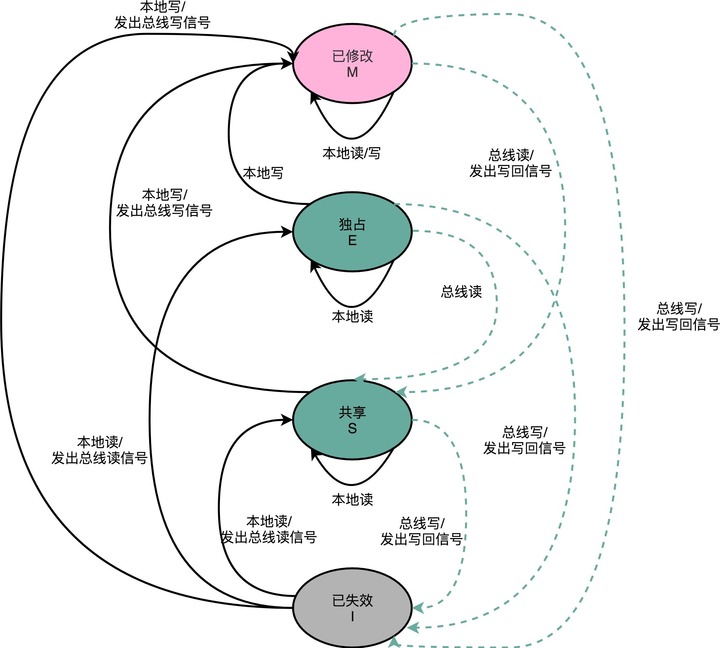
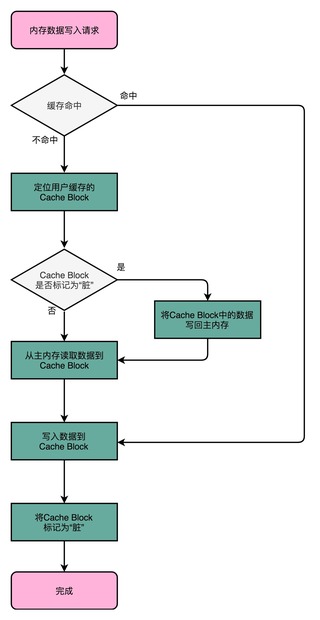
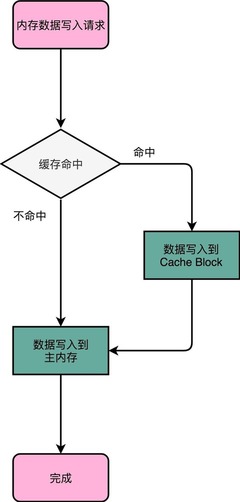
Content #
实际上,不对称结果是本书的核心思想:我永远不可能知道未知,因为从定义上讲,它是未知的。但是,我总是可以猜测它会怎样影响我,并且我应该基于这一点做出自己的决策。
这一观点通常被错误地称为“帕斯卡的赌注”,取自哲学家及(思想)数学家布莱斯·帕斯卡。他的观点如下:我不知道上帝是否存在,但我知道,如果他存在,我做无神论者就会损失很大,而假如他不存在,做无神论者也得不到好处,所以我应该相信上帝。
但帕斯卡的赌注背后的思想在神学之外有十分重要的用途。它颠覆了整个知识的概念,消除了理解稀有事件的可能性的必要(我们对于这一问题的知识有根本上的局限性);相反,我们可以只关注某个事件发生带给我们的好处。
稀有事件的概率是不可计算的;确定一个事件对我们的影响却容易得多(事件越稀有,可能性越模糊)。我们能清楚地知道某个事件的影响,即使我们不知道它发生的可能性。我不知道地震的可能性,但我能想象地震对旧金山会造成怎样的影响。做决策时,你只需要了解事件的影响(这是你能知道的),不需要了解事件的可能性(这是你不可能知道的),这一思想就是不确定性的核心思想。我生活的大部分都以它为基础。
From #
黑天鹅