Content #
官方的说法,Java 档案类是用来表示不可变数据的透明载体。其中“透明载体”的含义是什么?
通俗地说,就是档案类承载有缺省实现的方法,这些方法可以直接使用,也可以替换掉。档案类内置了下面的这些方法缺省实现:
- 构造方法
- equals 方法
- hashCode 方法
- toString 方法
- 不可变数据的读取方法
 November 9, 2022
November 9, 2022
November 9, 2022
November 9, 2022
中断信号来自哪个引脚,8259 芯片是最清楚的,所以它会把对应的中断号告诉处理器,处理器拿着这个中断号,要顺序做以下几件事。
和可屏蔽中断不同,NMI 发生时,处理器不会从外部获得中断号,它自动生成中断号码2,其他处理过程和可屏蔽中断相同。
November 9, 2022
November 9, 2022
November 9, 2022
November 9, 2022
可屏蔽中断是通过INTR 引脚进入处理器内部的,不可能为每一个中断源都提供一个引脚。而且,处理器每次只能处理一个中断。在这种情况下,需要一个代理,来接受外部设备发出的中断信号。还有,多个设备同时发出中断请求的几率也是很高的,所以该代理的任务还包括对它们进行仲裁,以决定让它们中的哪一个优先向处理器提出服务请求。
在个人计算机中,用得最多的中断代理就是8259 芯片,它就是通常所说的中断控制器,从8086 处理器开始,它就一直提供着这种服务。即使是现在,在绝大多数单处理器的计算机中,也依然有它的存在。
Intel 处理器允许256 个中断,中断号的范围是0~255,8259 负责提供其中的 15 个,但中断号并不固定。之所以不固定,是因为当初设计的时候,允许软件根据自己的需要灵活设置中断号,以防止发生冲突。该中断控制器芯片有自己的端口号,可以像访问其他外部设备一样用in 和out 指令来改变它的状态,包括各引脚的中断号。正是因为这样,它又叫可编程中断控制器(Programmable Interrupt Controller,PIC)。
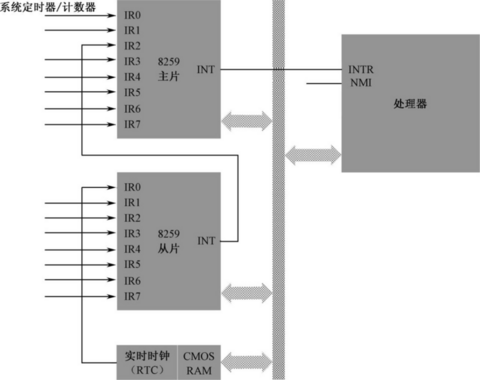 单处理器系统的中断机制
单处理器系统的中断机制
每片8259 只有8 个中断输入引脚,而在个人计算机上使用它,需要两块。如图所示,第一块8259 芯片的代理输出INT 直接送到处理器的INTR 引脚,这是主片(Master);第二块8259 芯片的INT 输出送到第一块的引脚2 上,是从片(Slave),两块芯片之间形成级联(Cascade)关系。如此一来,两块8259 芯片可以向处理器提供15 个中断信号。当时,接在8259 上的15 个设备都是相当重要的,如PS/2 键盘和鼠标、串行口、并行口、软磁盘驱动器、IDE 硬盘等。现在,这些设备很多都已淘汰或者正在淘汰中,根据需要,这些中断引脚可以被其他设备使用。
November 9, 2022
November 8, 2022
下面两种Java加锁的方式有何区别?方式一:
public class Logger {
private FileWriter writer;
public Logger() {
File file = new File("/Users/wangzheng/log.txt");
writer = new FileWriter(file, true); //true表示追加写入
}
public void log(String message) {
synchronized(this) {
writer.write(mesasge);
}
}
}
方式二:
public class Logger {
private FileWriter writer;
public Logger() {
File file = new File("/Users/wangzheng/log.txt");
writer = new FileWriter(file, true); //true表示追加写入
}
public void log(String message) {
synchronized(Logger.class) { // 类级别的锁
writer.write(mesasge);
}
}
}
方式一使用的是一个对象级别的锁,一个对象在不同的线程下同时调用 log() 函数,会被强制要求顺序执行。但是,不同的对象之间并不共享同一把锁。在不同的线程下,通过不同的对象调用执行 log() 函数,锁并不会起作用,仍然有可能存在写入日志互相覆盖的问题。
方式二把对象级别的锁,换成类级别的锁就可以了。让所有的对象都共享同一把锁。这样就避免了不同对象之间同时调用 log() 函数,而导致的日志覆盖问题。
...
November 8, 2022
米尔格拉姆的实验对象并非无可救药地容易上当受骗。他们产生过怀疑,而且是很多怀疑!吉娜·佩里的书《电击仪的背后》有趣地记录了“顺从实验”的全部经过,书中写道,吉娜·佩里曾采访了米尔格拉姆的原始实验对象中的一个,那是一位已退休的名叫乔·迪莫的工具师。迪莫告诉佩里:“我当时在想,‘这太奇怪了’。”迪莫在一开始相信华莱士是假装的。
我说我不知道到底发生了什么,但我有我的怀疑。我想:“如果我的怀疑是正确的,那么他(‘学生’)就是与他们串通好的。肯定是这样的。我根本就没有发出电击,但他却不时地叫喊。”
但在实验的最后,华莱士先生从锁着的房间里出来,稍稍“表演”了一会儿。迪莫记得,他看上去面容“憔悴”,神色可怜。“他手里拿着手帕,擦着脸走了进来。他走到我面前,伸出手和我握手,他说:‘我得感谢你停止了电击。’……当他进来时,我想:‘哦,也许这是真的。’”迪莫很确定自己被骗了,但是,一个撒谎者只需要继续略施演技——装出沮丧的样子,用手帕擦擦额头——就能让迪莫改变主意。
来看看米尔格拉姆实验的完整数据:

超过40%的志愿者注意到了实验中的一些猫腻,这表明实验并不像他们被告知的那样。但这些疑虑不足以使他们放弃“默认真实”——这就是莱文的观点。你相信某人不是因为你对他们没有怀疑,相信不代表没有怀疑;你相信一个人,是因为你对他没有足够多的怀疑。
我要重申一下“一些”疑问和“足够多的”疑问之间的区别,因为我认为这很关键。想想看,你曾经多少次事后聪明,因为别人没能识别谎言而用这样的话批评他们:“你应该知道的”,“曾有各种各样的、应该引起你警觉的可疑迹象”,“你有过怀疑”。莱文会说,这种看待问题的方式是错误的,你该问的正确问题应该是:是否曾有足够多的可疑迹象将你推出相信的门槛?因为凡人都会“默认真实”,如果没有足够多的可疑迹象,那么你只是常人而已。
November 8, 2022
莱文研究的目标是试图解决人类心理学中最大的难题之一:为什么我们在识别谎言方面如此糟糕?你可能会认为我们在这方面能做得很好。而且,如果人类能知道自己什么时候被欺骗了,那将是非常有用的。长达数百万年的进化本该偏袒一下人类,使其具备识别细微欺骗迹象的能力,但它却没有。
在莱文的一次实验中,他把他的录像分成了两部分:录的分别是22个撒谎者和22 个说真话的人。然后一些被试被要求看完这44个人的录像,辨认出说谎者。实验结果显示,人们能辨认出说谎者的平均正确率是56%。其他心理学家也做过类似的实验,他们的平均正确率是多少呢?54%。几乎每个人在辨认说谎者方面都是糟糕的:警察、法官、心理学家,甚至在国外负责大型间谍网络的中情局官员。为什么会这样?
蒂姆·莱文的答案是被简称为TDT的“默认真实”理论。
莱文的论证始于他的一个研究生朴善熙提出的见解。研究初期,莱文和同行一样,困惑于为什么我们那么不擅长去做按理说应该擅长的事情。
莱文说:“朴善熙的第一个重大发现是,54%的准确率是正确辨别真话和谎言的平均值。换个角度来看,你就会有完全不同的发现……可以观察有多少人能正确辨别真话,又有多少人能正确辨别谎言。”
他的意思是这样的。如果我告诉你辨别莱文录像中的人是否说谎的正确率在50% 左右,人们自然会认为,你只是随机猜测——你并不知道该如何辨别谎言。但朴善熙观察后发现,这不是真的:我们在正确识别说真话的学生方面,比随机猜测做得好;在正确识别说谎的学生方面,做得比随机猜测差。我们在看完了所有的录像后,就觉得“对,对,对”,这意味着我们正确地认识了大多数对说真话的人的采访,但却错误地认识了大多数对说谎者的采访。我们会“默认真实”:我们常用的假设是,与我们打交道的人是诚实的。