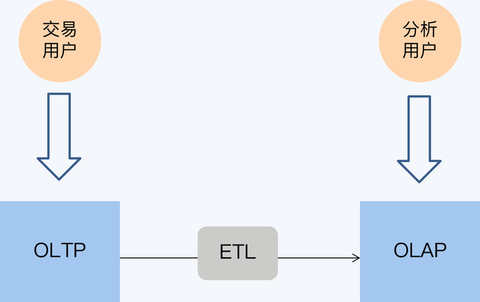
Content #
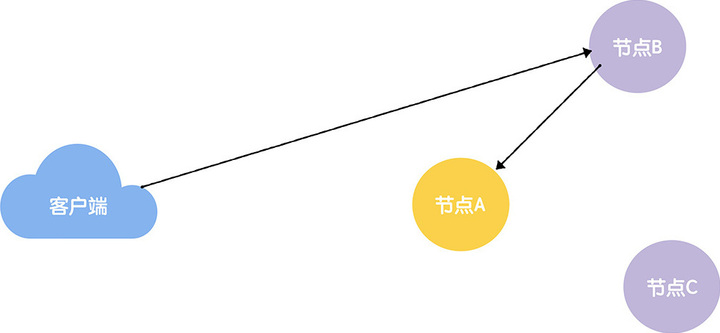
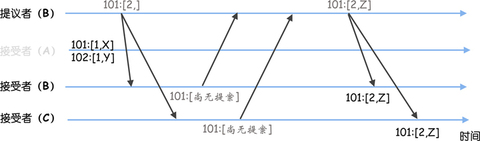
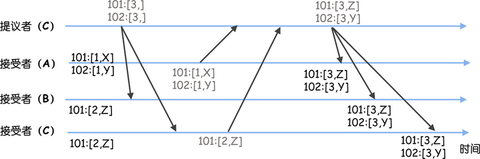
事务标识符(Transaction ID,也就是 zxid),就像下图的样子。
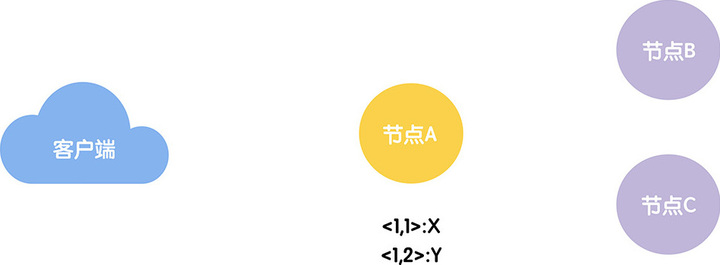
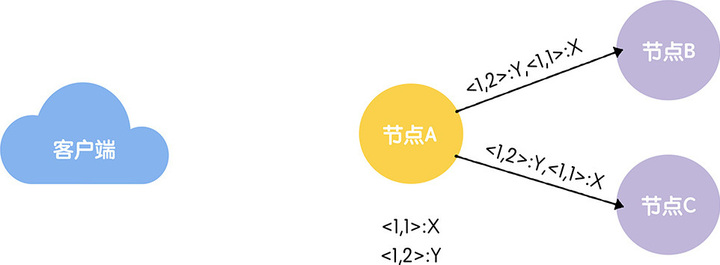
从图中你可以看到,X、Y 对应的事务标识符分别为 <1, 1> 和 <1, 2>,这两个标识符是什么含义呢?
你可以这么理解,事务标识符是 64 位的 long 型变量,有任期编号 epoch 和计数器 counter 两部分组成(为了形象和方便理解,我把 epoch 翻译成任期编号),格式为 <epoch, counter>,高 32 位为任期编号,低 32 位为计数器:
-
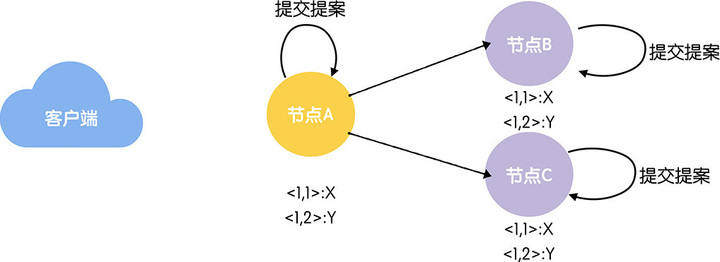
任期编号,就是创建提案时领导者的任期编号,需要你注意的是,当新领导者当选时,任期编号递增,计数器被设置为零。比如,前领导者的任期编号为 1,那么新领导者对应的任期编号将为 2。
-
计数器,就是具体标识提案的整数,需要你注意的是,每次领导者创建新的提案时,计数器将递增。比如,前一个提案对应的计数器值为 1,那么新的提案对应的计数器值将为 2。
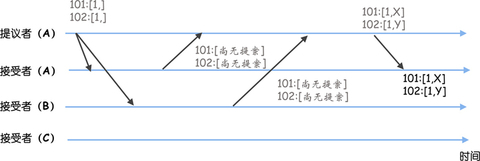
为什么要设计的这么复杂呢?因为事务标识符必须按照顺序、唯一标识一个提案,也就是说,事务标识符必须是唯一的、递增的。