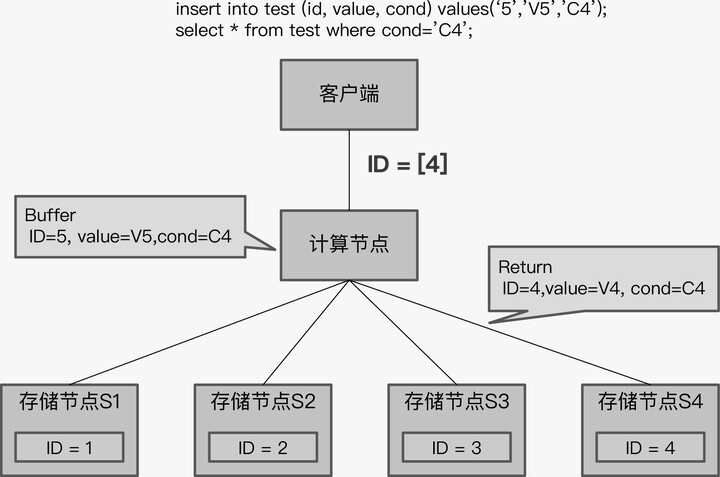
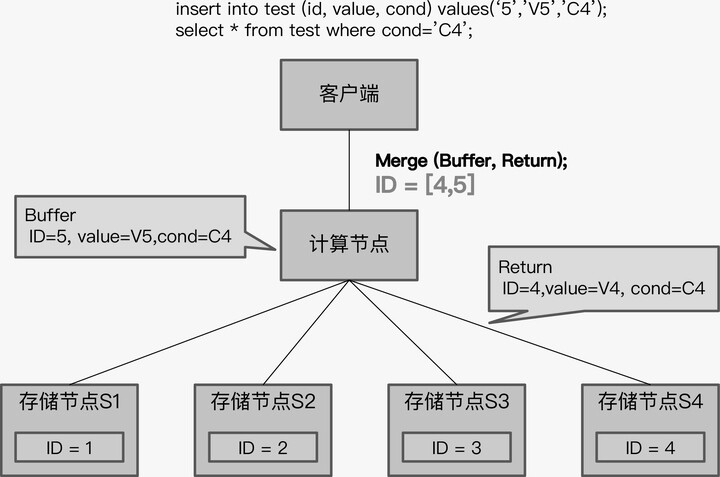
begin;
insertinto test (id, value, cond) values(‘5’,’V5’,’C4’);
select*from test where cond=’C4’;
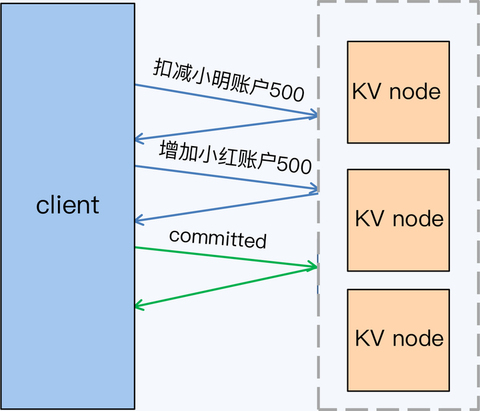
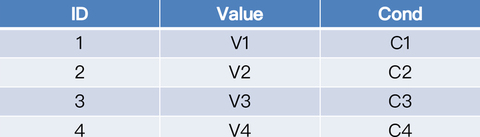
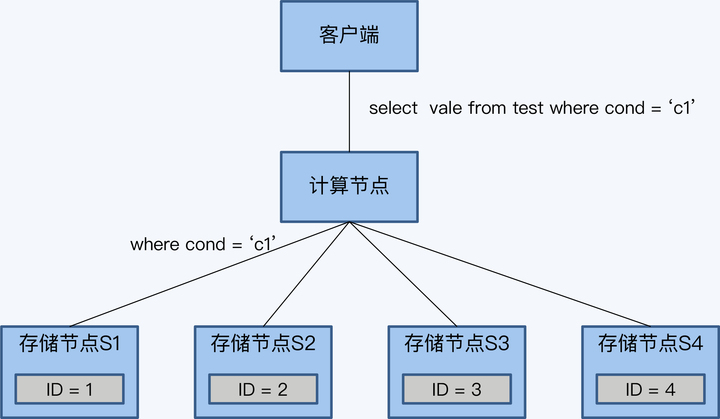
SQL 的逻辑很简单,先插入一条记录后,再查询符合条件的所有记录。结合上一个例子中 test 表的数据存储情况,得到的查询结果应该是两条记录,一条是原有 ID 等于 4 的记录,另一条是刚插入的 ID 等于 5 的记录。这对单体数据库来说,是很平常的操作,但是对于 TiDB 来说,就是一个有挑战的事情了。
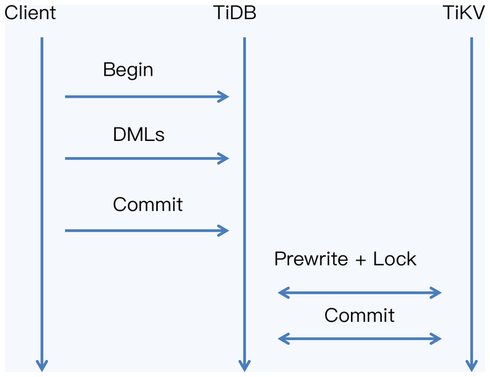
TiDB 采用了“缓存写提交”技术,就是将所有的写 SQL 缓存起来,直到事务
commit 时,再一起发送给存储节点。这意味着执行事务中的 select 语句时,
insert 的数据还没有写入存储节点,而是缓存在计算节点上的,那么 select
语句下推后,查询结果将只有 ID 为 4 的记录,没有 ID 等于 5 的记录。