Content
#
如果我们想要让函数组件更有用,目标就是给函数组件加上状态。这看上去似乎并不是难事。
简单想一下,函数和对象不同,并没有一个实例的对象能够在多次执行之间保存状态,那势必需要一个函数之外的空间来保存这个状态,而且要能够检测其变化,从而能够触发函数组件的重新渲染。
再进一步想,那我们是不是就是需要这样一个机制,能够把一个外部的数据绑定到函数的执行。当数据变化时,函数能够自动重新执行。这样的话,任何会影响
UI 展现的外部数据,都可以通过这个机制绑定到 React 的函数组件。
在 React 中,这个机制就是 Hooks。
顾名思义,Hook 就是“钩子”的意思。在 React 中,Hooks 就是把某个目标结果钩到某个可能会变化的数据源或者事件源上,那么当被钩到的数据或事件发生变化时,产生这个目标结果的代码会重新执行,产生更新后的结果。
对于函数组件,这个结果是最终的 DOM 树;对于 useCallback、useMemo 这样与缓存相关的组件,则是在依赖项发生变化时去更新缓存。所以 Hooks 的结构可以如下图所示:
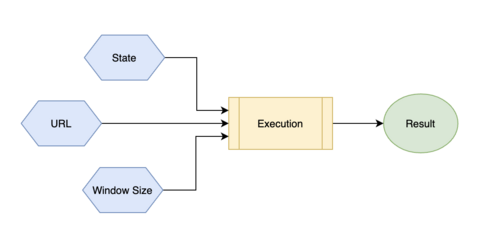
从图中可以看到,一个执行过程(Execution),例如是函数组件本身,可以绑定在(钩在)传统意义的 State,或者 URL,甚至可以是窗口的大小。这样当
State、URL、窗口大小发生变化时,都会重新执行某个函数,产生更新后的结果。
当然,既然我们的初衷是为了实现 UI 组件的渲染,那么在 React 中,其实所有的 Hooks 的最终结果都是导致 UI 的变化。但是正如 React 官方曾经提到过的,Hooks 的思想其实不仅可以用在 React,在其它一些场景也可以被利用。
Viewpoints
#
From
#
02|理解 Hooks:React 为什么要发明 Hooks?
Links
#

![$$U=span[x_1, x_2, \cdots, x_m]$$](/ltximg/20221114212039-求向量子空间的基_5b9272a7ab929f5ab080c50cf7f679ec4bae45b0.svg)
 组合成矩阵 A 的列;
组合成矩阵 A 的列;