Content #
在输入 qa时,Vim将开始录制接下来的按键操作,并将它们保存到寄存器 a中,这会覆盖该寄存器原有的内容。
如果输入的是 qA,Vim也会录制按键操作,但会把它们附加到寄存器 a原有的内容之后。可以用这种方式给宏追加命令。
这条小技巧把我们从“被迫重新录制宏”的窘境中解救出来。但此法只能在宏的结尾添加命令,如果想在宏的开头或者中间的某个位置添加内容,它就无能为力了。
 November 15, 2022
November 15, 2022
November 15, 2022
November 15, 2022
首先,为这组要处理的文件建立一个文件列表。我们将用参数列表记录这些文件: :cd code/macros/ruby_module :args *.rb 不带参数运行:args命令,就可以显示参数列表中的内容。 :args [animal.rb] banker.rb frog.rb person.rb 而使用 :first、:last、:prev以及 :next命令,可以浏览整个文件列表。
在开始工作之前,首先要确保光标已经位于参数列表中的第一个文件中。 :first 现在录制一个宏,完成所有工作。做完后不要运行 :w 保存文件。
如果直接运行 :argdo normal @a,第一个缓冲区的内容将被两次执行同一个宏。为了避免此类问题,将执行 :edit! ,放弃针对第一个缓冲区所做的所有修改。 :edit! 如果所做的修改已经保存至文件,那么执行 :edit! 将起不到任何作用。在这种情况下,只能重复使用 u命令直到恢复成原样。现在可在参数列表的所有缓冲区内执行宏了。 :argdo normal @a
在宏的最后附加一个步骤:next跳转至列表中的下一个缓冲区。虽然可以运行 3@a,让宏在缓冲区列表余下的每个文件中得以执行,但是,次数没必要那么精确。这是因为,宏一旦执行到参数列表的最后一个缓冲区,:next 命令将会失败,宏将中止退出。所以与其指定一个精确的数值,倒不如保证数字足够大。22这个数字就可以,而且很容易输入。
运行 :argdo write可保存参数列表中的全部文件,但如果简单地运行以下命令,会更快。 :wall
另一条有用的命令是 :wnext(参见 :h :wn ),它等同于先运行 :write,再运行 :next。如果想用串行的方式,在参数列表的多个文件上执行宏,可能更愿意用这条命令。
November 15, 2022
以计数器例子为例,来讲解如何在 React 中使用 Redux:
import React from 'react'
import { useSelector, useDispatch } from 'react-redux'
export function Counter() {
// 从 state 中获取当前的计数值
const count = useSelector(state => state.value)
// 获得当前 store 的 dispatch 方法
const dispatch = useDispatch()
// 在按钮的 click 时间中去分发 action 来修改 store
return (
<div>
<button
onClick={() => dispatch({ type: 'counter/incremented' })}
>+</button>
<span>{count}</span>
<button
onClick={() => dispatch({ type: 'counter/decremented' })}
>-</button>
</div>
)
}
此外,通过计数器这个例子,我们还可以看到 React 和 Redux 共同使用时的单向数据流:
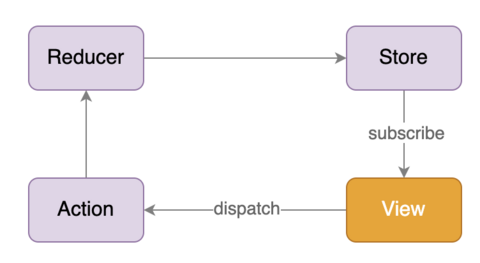
需要强调的是,在实际的使用中,我们无需关心 View 是如何绑定到 Store 的某一部分数据的,因为 React-Redux 帮我们做了这件事情。总结来说,通过这样一种简单的机制,Redux 统一了更新数据状态的方式,让整个应用程序更加容易开发、维护、调试和测试。
November 15, 2022
那么如何建立 Redux 和 React 的联系呢?
主要是两点:
要实现这两点,我们需要引入 Facebook 提供的 react-redux 这样一个工具库,工具库的作用就是建立一个桥梁,让 React 和 Redux 实现互通。
在 react-redux 的实现中,为了确保需要绑定的组件能够访问到全局唯一的 Redux Store,利用了 React 的 Context 机制去存放 Store 的信息。通常我们会将这个 Context 作为整个 React 应用程序的根节点。因此,作为 Redux 的配置的一部分,我们通常需要如下的代码:
import React from 'react'
import ReactDOM from 'react-dom'
import { Provider } from 'react-redux'
import store from './store'
import App from './App'
const rootElement = document.getElementById('root')
ReactDOM.render(
<Provider store={store}>
<App />
</Provider>,
rootElement
)
这里使用了 Provider 这样一个组件来作为整个应用程序的根节点,并将 Store 作为属性传给了这个组件,这样所有下层的组件就都能够使用 Redux 了。
...
November 15, 2022
Redux 引入的概念其实并不多,主要就是三个:State、Action 和 Reducer。
它们三者之间的关系可以用下图来表示:
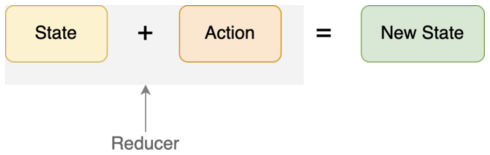
在 Redux 中,所有对于 Store 的修改都必须通过这样一个公式去完成,即通过 Reducer 完成,而不是直接修改 Store。这样的话,一方面可以保证数据的不可变性(Immutable),同时也能带来两个非常大的好处。
比如说要实现“加一”和“减一”这两个功能,对于 Redux 来说,我们需要如下代码:
import { createStore } from 'redux'
// 定义 Store 的初始值
const initialState = { value: 0 }
// Reducer,处理 Action 返回新的 State
function counterReducer(state = initialState, action) {
switch (action.type) {
case 'counter/incremented':
return { value: state.value + 1 }
case 'counter/decremented':
return { value: state.value - 1 }
default:
return state
}
}
// 利用 Redux API 创建一个 Store,参数就是 Reducer
const store = createStore(counterReducer)
// Store 提供了 subscribe 用于监听数据变化
store.subscribe(() => console.log(store.getState()))
// 计数器加 1,用 Store 的 dispatch 方法分发一个 Action,由 Reducer 处理
const incrementAction = { type: 'counter/incremented' };
store.dispatch(incrementAction);
// 监听函数输出:{value: 1}
// 计数器减 1
const decrementAction = { type: 'counter/decremented' };
store.dispatch(decrementAction)
// 监听函数输出:{value: 0}
通过这段代码,我们就用三个步骤完成了一个完整的 Redux 的逻辑:
...
November 15, 2022
在组件的开发过程中,有一些常用的通用逻辑。过去可能会因为逻辑重用比较繁琐,而经常在每个组件中去自己实现,造成维护的困难。但现在有了 Hooks,就可以将更多的通用逻辑通过 Hooks 的形式进行封装,方便被不同的组件重用。
比如说,在日常 UI 的开发中,有一个最常见的需求:发起异步请求获取数据并显示在界面上。在这个过程中,我们不仅要关心请求正确返回时,UI 会如何展现数据;还需要处理请求出错,以及关注 Loading 状态在 UI 上如何显示。
我们可以看下异步请求的例子,从 Server 端获取用户列表,并显示在界面上:
import React from "react";
export default function UserList() {
// 使用三个 state 分别保存用户列表,loading 状态和错误状态
const [users, setUsers] = React.useState([]);
const [loading, setLoading] = React.useState(false);
const [error, setError] = React.useState(null);
// 定义获取用户的回调函数
const fetchUsers = async () => {
setLoading(true);
try {
const res = await fetch("https://reqres.in/api/users/");
const json = await res.json();
// 请求成功后将用户数据放入 state
setUsers(json.data);
} catch (err) {
// 请求失败将错误状态放入 state
setError(err);
}
setLoading(false);
};
return (
<div className="user-list">
<button onClick={fetchUsers} disabled={loading}>
{loading ? "Loading..." : "Show Users"}
</button>
{error &&
<div style={{ color: "red" }}>Failed: {String(error)}</div>
}
<br />
<ul>
{users && users.length > 0 &&
users.map((user) => {
return <li key={user.id}>{user.first_name}</li>;
})}
</ul>
</div>
);
}
在这里,我们定义了 users、loading 和 error 三个状态。如果我们在异步请求的不同阶段去设置不同的状态,这样 UI 最终能够根据这些状态展现出来。在每个需要异步请求的组件中,其实都需要重复相同的逻辑。
...
November 15, 2022
我们需要展示一个博客文章的列表,并且有一列要显示文章的分类。同时,我们还需要提供表格过滤功能,以便能够只显示某个分类的文章。
为了支持过滤功能,后端提供了两个 API:一个用于获取文章的列表,另一个用于获取所有的分类。这就需要我们在前端将文章列表返回的数据分类 ID 映射到分类的名字,以便显示在列表里。
这时候,如果按照直观的思路去实现,通常都会把逻辑都写在一个组件里,比如类似下面的代码:
function BlogList() {
// 获取文章列表...
// 获取分类列表...
// 组合文章数据和分类数据...
// 根据选择的分类过滤文章...
// 渲染 UI ...
}
这会造成某个函数组件特别长。改变这个状况的关键仍然在于开发思路的转变。我们要真正把 Hooks 就看成普通的函数,能隔离的尽量去做隔离,从而让代码更加模块化,更易于理解和维护。
那么针对这样一个功能,我们甚至可以将其拆分成 4 个 Hooks,每一个 Hook 都尽量小,代码如下:
import React, { useEffect, useCallback, useMemo, useState } from "react";
import { Select, Table } from "antd";
import _ from "lodash";
import useAsync from "./useAsync";
const endpoint = "https://myserver.com/api/";
const useArticles = () => {
// 使用上面创建的 useAsync 获取文章列表
const { execute, data, loading, error } = useAsync(
useCallback(async () => {
const res = await fetch(`${endpoint}/posts`);
return await res.json();
}, []),
);
// 执行异步调用
useEffect(() => execute(), [execute]);
// 返回语义化的数据结构
return {
articles: data,
articlesLoading: loading,
articlesError: error,
};
};
const useCategories = () => {
// 使用上面创建的 useAsync 获取分类列表
const { execute, data, loading, error } = useAsync(
useCallback(async () => {
const res = await fetch(`${endpoint}/categories`);
return await res.json();
}, []),
);
// 执行异步调用
useEffect(() => execute(), [execute]);
// 返回语义化的数据结构
return {
categories: data,
categoriesLoading: loading,
categoriesError: error,
};
};
const useCombinedArticles = (articles, categories) => {
// 将文章数据和分类数据组合到一起
return useMemo(() => {
// 如果没有文章或者分类数据则返回 null
if (!articles || !categories) return null;
return articles.map((article) => {
return {
...article,
category: categories.find(
(c) => String(c.id) === String(article.categoryId),
),
};
});
}, [articles, categories]);
};
const useFilteredArticles = (articles, selectedCategory) => {
// 实现按照分类过滤
return useMemo(() => {
if (!articles) return null;
if (!selectedCategory) return articles;
return articles.filter((article) => {
console.log("filter: ", article.categoryId, selectedCategory);
return String(article?.category?.name) === String(selectedCategory);
});
}, [articles, selectedCategory]);
};
const columns = [
{ dataIndex: "title", title: "Title" },
{ dataIndex: ["category", "name"], title: "Category" },
];
export default function BlogList() {
const [selectedCategory, setSelectedCategory] = useState(null);
// 获取文章列表
const { articles, articlesError } = useArticles();
// 获取分类列表
const { categories, categoriesError } = useCategories();
// 组合数据
const combined = useCombinedArticles(articles, categories);
// 实现过滤
const result = useFilteredArticles(combined, selectedCategory);
// 分类下拉框选项用于过滤
const options = useMemo(() => {
const arr = _.uniqBy(categories, (c) => c.name).map((c) => ({
value: c.name,
label: c.name,
}));
arr.unshift({ value: null, label: "All" });
return arr;
}, [categories]);
// 如果出错,简单返回 Failed
if (articlesError || categoriesError) return "Failed";
// 如果没有结果,说明正在加载
if (!result) return "Loading...";
return (
<div>
<Select
value={selectedCategory}
onChange={(value) => setSelectedCategory(value)}
options={options}
style={{ width: "200px" }}
placeholder="Select a category"
/>
<Table dataSource={result} columns={columns} />
</div>
);
}
通过这样的方式,我们就把一个较为复杂的逻辑拆分成一个个独立的 Hook 了,不仅隔离了业务逻辑,也让代码在语义上更加明确。比如说有 useArticles、 useCategories 这样与业务相关的名字,就非常易于理解。
...
November 15, 2022
虽然 React 组件基本上不需要关心太多的浏览器 API,但是有时候却是必须的:
这都需要用到浏览器的 API 来监听这些状态的变化。那么我们就以滚动条位置的场景为例,来看看应该如何用 Hooks 优雅地监听浏览器状态。
正如 Hooks 的字面意思是“钩子”,它带来的一大好处就是:可以让 React 的组件绑定在任何可能的数据源上。这样当数据源发生变化时,组件能够自动刷新。把这个好处对应到滚动条位置这个场景就是:组件需要绑定到当前滚动条的位置数据上。
虽然这个逻辑在函数组件中可以直接实现,但是把这个逻辑实现为一个独立的 Hooks,既可以达到逻辑重用,在语义上也更加清晰。这个和上面的 useAsync 的作用是非常类似的。
我们可以直接来看这个 Hooks 应该如何实现:
import { useState, useEffect } from 'react';
// 获取横向,纵向滚动条位置
const getPosition = () => {
return {
x: document.body.scrollLeft,
y: document.body.scrollTop,
};
};
const useScroll = () => {
// 定一个 position 这个 state 保存滚动条位置
const [position, setPosition] = useState(getPosition());
useEffect(() => {
const handler = () => {
setPosition(getPosition(document));
};
// 监听 scroll 事件,更新滚动条位置
document.addEventListener("scroll", handler);
return () => {
// 组件销毁时,取消事件监听
document.removeEventListener("scroll", handler);
};
}, []);
return position;
};
有了这个 Hook,你就可以非常方便地监听当前浏览器窗口的滚动条位置了。比如下面的代码就展示了“返回顶部”这样一个功能的实现:
...
November 15, 2022
在类组件中,componentDidMount,componentWillUnmount,和 componentDidUpdate 这三个生命周期方法可以说是日常开发最常用的。业务逻辑通常要分散到不同的生命周期方法中,比如说在上面的 Blog 文章的例子中,你需要同时在 componentDidMount 和 componentDidUpdate 中去获取数据。
而在函数组件中,这几个生命周期方法可以统一到 useEffect 这个 Hook,正如 useEffect 的字面含义,它的作用就是触发一个副作用,即在组件每次 render 之后去执行。
下面的代码演示了这三个生命周期方法是如何用 useEffect 实现的:
useEffect(() => {
// componentDidMount + componentDidUpdate
console.log('这里基本等价于 componentDidMount + componentDidUpdate');
return () => {
// componentWillUnmount
console.log('这里基本等价于 componentWillUnmount');
}
}, [deps])
可以看到,useEffect 接收的 callback 参数,可以返回一个用于清理资源的函数,从而在下一次同样的 Effect 被执行之前被调用。
你可能已经注意到了,在代码里我用了“基本等价于”这个说法,什么意思呢?指的就是这个写法并没有完全等价于传统的这几个生命周期方法。主要有两个原因。
一方面,useEffect(callback) 这个 Hook 接收的 callback,只有在依赖项变化时才被执行。而传统的 componentDidUpdate 则一定会执行。这样来看,Hook 的机制其实更具有语义化,因为过去在 componentDidUpdate 中,我们通常都需要手动判断某个状态是否发生变化,然后再执行特定的逻辑。
另一方面,callback 返回的函数(一般用于清理工作)在下一次依赖项发生变化以及组件销毁之前执行,而传统的 componentWillUnmount 只在组件销毁时才会执行。
第二点可能有点难理解,我们不妨继续看博客文章这个例子。假设当文章 id 发生变化时,我们不仅需要获取文章,同时还要监听某个事件,这样在有新的评论时获得通知,就能显示新的评论了。这时候的代码结构如下:
...
November 15, 2022
利用 useRef 这个 Hook,我们可以实现一个 useSingleton 这样的一次性执行某段代码的自定义 Hook,代码如下:
import { useRef } from 'react';
// 创建一个自定义 Hook 用于执行一次性代码
function useSingleton(callback) {
// 用一个 called ref 标记 callback 是否执行过
const called = useRef(false);
// 如果已经执行过,则直接返回
if (called.current) return;
// 第一次调用时直接执行
callBack();
// 设置标记为已执行过
called.current = true;
}
从而在一个函数组件中,可以调用这个自定义 Hook 来执行一些一次性的初始化逻辑:
import useSingleton from './useSingleton';
const MyComp = () => {
// 使用自定义 Hook
useSingleton(() => {
console.log('这段代码只执行一次');
});
return (
<div>My Component</div>
);
};
代码中可以看到,useSingleton 这个 Hook 的核心逻辑就是定义只执行一次的代码。而是否在所有代码之前执行,则取决于在哪里调用,可以说,它的功能其实是包含了构造函数的功能的。
如果想要实现只执行一次的功能,用useEffect,依赖项传空数组,不是可以实现吗?为什么要写一个自定义钩子?作者回复: 因为需要在函数体执行之前执行。useEffect 是在 render 完后执行。
...