Content #
RPO(Recovery Point Object),灾难发生后,系统和数据必须恢复到的时间点要求。是衡量灾难发生后会丢失多少生产数据的指标。可简单的描述为设施能容忍的最大数据丢失量。
 November 27, 2022
November 27, 2022
November 27, 2022
November 27, 2022
双向同步模式下,同城和异地的数据库同时提供服务,并且是读写服务均开放。但有一个重要的约束,就是两地读写的对象必须是不同的数据,区分方式可以是不同的表或者表内的不同记录,这个约束是为了保证两地数据操作不会冲突。因为不需要处理跨区域的事务冲突,所以两地数据库之间就可以采用异步同步的方式。
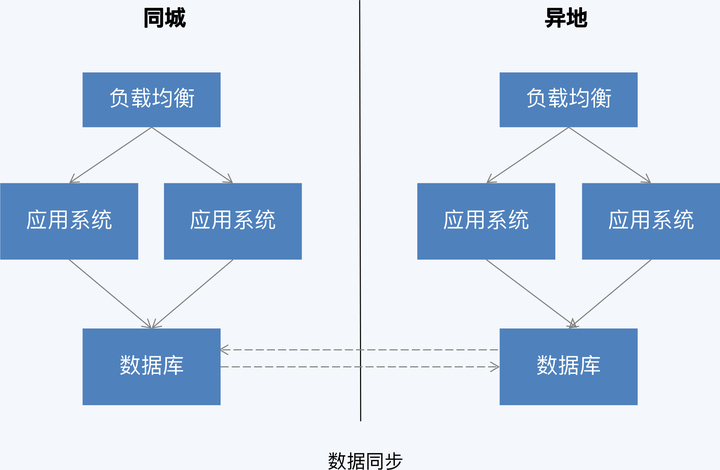
这个模式下,两地处理的数据是泾渭分明的,所以实质上是两个独立的应用实例,或者可以说是两个独立的单元,也就是单元化架构。而两个单元之间又相互备份数据,有了这些数据可以容灾,也可以开放只读服务。当然,这个只读服务同样是不保证数据一致性的。
可以说,双向同步是单元化架构和异地读写分离的混合,异地机房的资源被充分使用了。但双向同步没有解决一个根本问题,就是两地仍然不能处理同样的数据,对于一个完整的系统来说,这还是有很大局限性的。
November 27, 2022
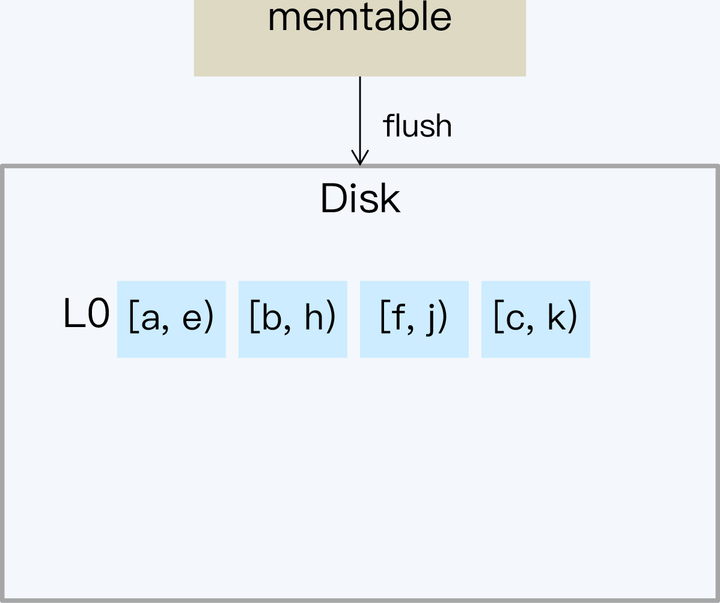
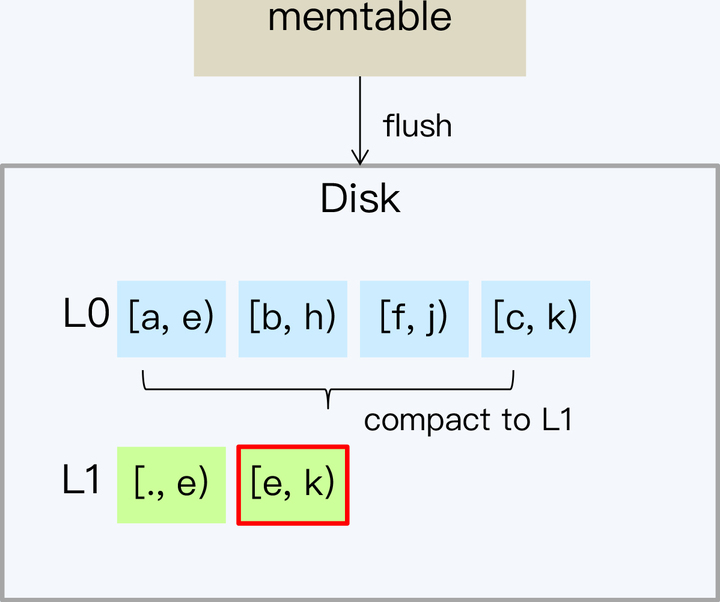
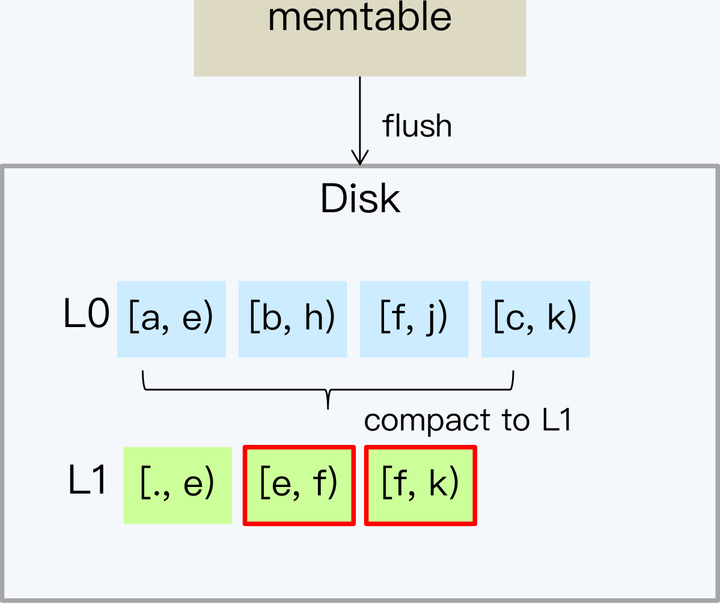
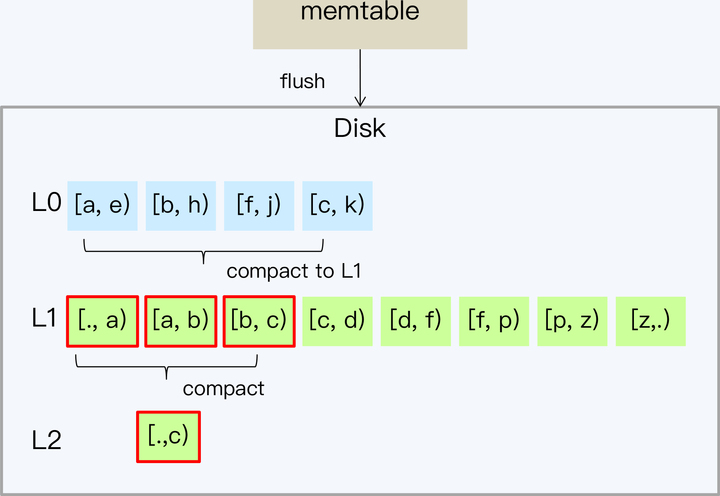
Tiered 策略之所以有严重的写放大和空间放大问题,主要是因为每次 Compact 需要全量数据参与,开销自然就很大。那么如果每次只处理小部分 SSTable 文件,就可以改善这个问题了。
Leveled 就是这个思路,它的设计核心就是将数据分成一系列 Key 互不重叠且固定大小的 SSTable 文件,并分层(Level)管理。同时,系统记录每个 SSTable 文件存储的 Key 的范围。Leveled 策略最先在 LevelDB 中使用,也因此得名。后来从 LevelDB 上发展起来的 RocksDB 也采用这个策略。
接下来,我们详细说明一下这个处理过程。
说完处理流程,我们再从 RUM 三个角度来分析下。
...
November 27, 2022
合并策略Size-Tiered Compact Strategy,简称 Tiered。BigTable 和 HBase 都采用了 Tiered 策略。它的基本原理是,每当某个尺寸的 SSTable 数量达到既定个数时,将所有 SSTable 合并成一个大的 SSTable。这种策略的优点是比较直观,实现简单,但是缺点也很突出。下面我们从 RUM 的三个角度来分析下:
执行读操作时,由于单个 SSTable 内部是按照 Key 顺序排列的,那么查找方法的时间复杂度就是 O(logN)。因为 SSTable 文件是按照时间间隔产生的,在 Key 的范围上就会存在交叉,所以每次读操作都要遍历所有 SSTable。如果有 M 个 SSTable,整体时间复杂度就是 O(MlogN)。执行 Compact 后,时间复杂度降低为 O(log(MN))。在只有一个 SSTable 时,读操作没有放大。
Compact 会降低读放大,但却带来更多的写放大和空间放大。其实 LSM 只是推迟了写放大,短时间内,可以承载大量并发写入,但如果是持续写入,则需要一部分 I/O 开销用于处理 Compact。
你可能听说到过关于 B+Tree 和 LSM 的一个争论,就是到底谁的写放大更严重。如果是采用 Tiered 策略,LSM 的写放大比 B+Tree 还严重。此外,Compact 是一个很重的操作,占用大量的磁盘 I/O,会影响同时进行的读操作。
从空间放大的角度看,Tiered 策略需要有两倍于数据大小的空间,分别存储合并前的多个 SSTable 和合并后的一个 SSTable,所以 SAF 是 2,而 B+Tree 的 SAF 是 1.33。
...
November 27, 2022
LSM 分成三步完成了数据的落盘。
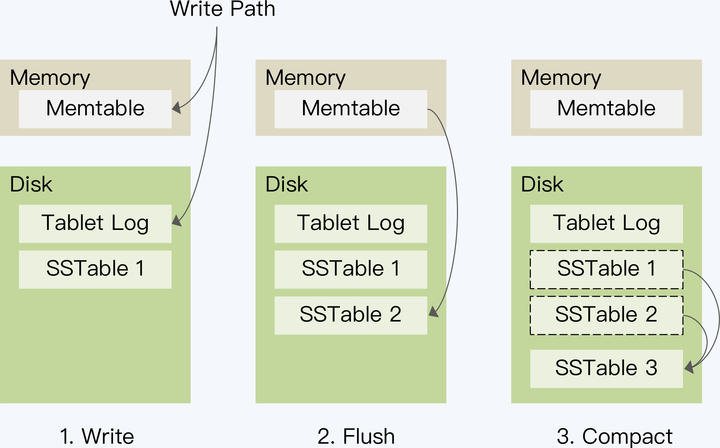
第一步,写入 Memtable,同时记录 Tablet Log;
当 Memtable 的数据达到一定阈值后,系统会把其冻结并将其中的数据顺序写入磁盘上的有序文件(Sorted String Table,SSTable)中,这个操作被称为 Flush;当然,执行这个动作的同时,系统会同步创建一个新的 Memtable,处理写入请求。
根据第二步的处理逻辑,Memtable 会周期性地产生 SSTable。当满足一定的规则时,这些 SSTable 会被合并为一个大的 SSTable。这个操作称为 Compact。
与 B+Tree 的最大不同是 LSM 将随机写转换为顺序写,这样提升了写入性能。另外,Flush 操作不会像 B+Tree 那样产生写放大。
真正的写放大就发生在 Compact 这个动作上。Compact 有两个关键点,一是选择什么时候执行,二是要将哪些 SSTable 合并成一个 SSTable。这两点加起来称为“合并策略”。
我们刚刚在例子中描述的就是一种合并策略,称为 Size-Tiered Compact Strategy,简称 Tiered。BigTable 和 HBase 都采用了 Tiered 策略。它的基本原理是,每当某个尺寸的 SSTable 数量达到既定个数时,将所有 SSTable 合并成一个大的 SSTable。这种策略的优点是比较直观,实现简单,但是缺点也很突出。
November 27, 2022
B+Tree 是对读操作优化的存储结构,能够支持高效的范围扫描,叶节点之间保留链接并且按主键有序排列,扫描时避免了耗时的遍历树操作。
下面这张图中展示了一棵高度为 2 的 B+Tree,数据存储在 5 个页表中,每页可存放 4 条记录。略去了叶子节点指向数据的指针以及叶子节点之间的顺序指针。
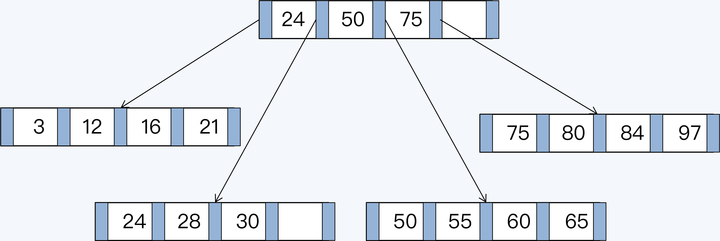
B+Tree 由内节点(InterNode)和叶节点(LeafNode)两类节点构成,前者仅包含索引信息,后者则携带了指向数据的指针。当插入一个索引值为 70 的记录,由于对应页表的记录已满,需要对 B+Tree 重新排列,变更其父节点所在页表的记录,并调整相邻页表的记录。完成重新分布后的效果如下:
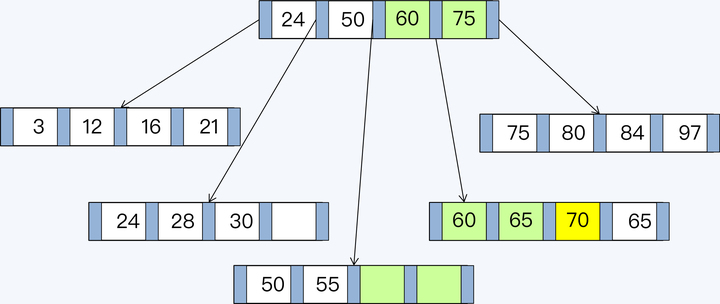
在这个写入过程中存在两个问题:
本来我们仅需要一条写入记录(黄色标注),实际上更新了 3 个页表中的 7 条索引记录,额外的 6 条记录(绿色标注)是为了维护 B+Tree 结构产生的写放大。
为了度量写放大的程度,相关研究中引入了写放大系数(Write Amplification Factor,WAF)这个指标,就是指实际写入磁盘的数据量和应用程序要求写入数据量之比。对于空间放大有类似的度量单位,也就是空间放大系数(Space Amplification Factor, SAF)。
我们这个例子中的 WAF 是 7。
虽然新增叶节点会加入到原有叶节点构成的有序链表中,整体在逻辑上是连续的,但是在磁盘存储上,新增页表申请的存储空间与原有页表很可能是不相邻的。这样,在后续包含新增叶节点的查询中,将会出现多段连续读取,磁盘寻址的时间将会增加。
也就是说,虽然 B+Tree 结构是为读取做了优化,但如果进行大量随机写还是会造成存储的碎片化,从而导致写放大和读放大。
填充因子(Factor Fill)是一种常见的优化方法,它的原理就是在页表中预留一些空间,这样不会因为少量的数据写入造成树结构的大幅变动。但填充因子的设置也很难拿捏,过大则无法解决写放大问题;过小会造成页表数量膨胀,增大对磁盘的扫描范围,降低查询性能。
November 27, 2022
RUM 猜想来自论文“Designing Access Methods: The RUM Conjecture”(Manos Athanassoulis et al.(2016)),同时被 SIGMOD 和 EDBT 收录。它说的是,对任何数据结构来说,在 Read Overhead(读)、 Update Overhead(写) 和 Memory or Storage Overhead(存储) 中,同时优化两项时,需要以另一项劣化作为代价。论文用一幅图展示了常见数据结构在这三个优化方向中的位置。
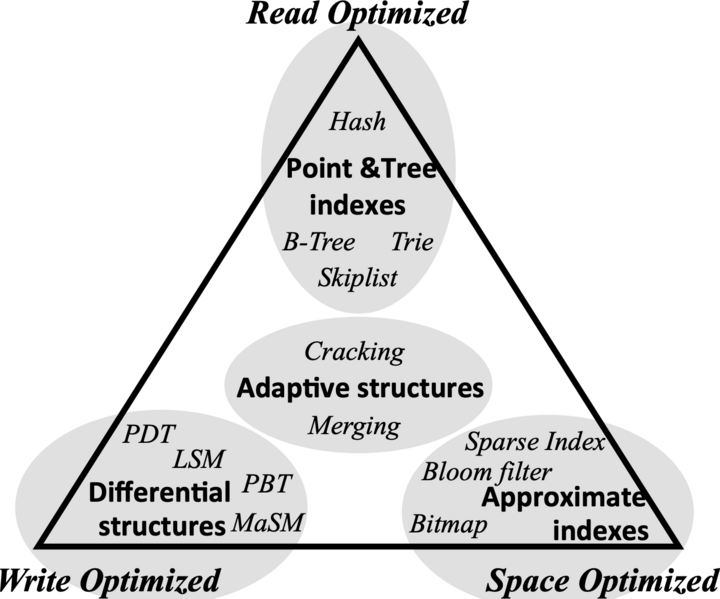
在这张图中,我们可以看到两个非常熟悉的数据结构 B-Tree 和 LSM,它们被用于分布式数据库的存储引擎中,前者(实际是 B+Tree,B-Tree 的变体)主要用于 PGXC,后者则主要用于 NewSQL。
November 27, 2022
November 27, 2022
价值观与现代化的冲突,在历史越是悠久、古代文化越是发达的民族,表现得越明显。中国如此,印度如此,许多伊斯兰教的国家也如此。而历史短的国家如美国,就没有这种包袱。博大精深的古文化成了现代化进程中的沉重负担。心理学家葛登纳(John W.Gardner)曾说:
那些企图逃避转变之潮流的人有一个诡计,即立足于高高在上的道德基地,他们断言固有的一切紧紧系于道德和精神之上,改变它们将威胁到这些道德和精神。当18和19世纪的俄国不得不面对西欧优势的工艺发展时,亲斯拉夫的人被迫绝口不提物质之落后,而大谈其俄罗斯的精神是如何高贵。这正像今天在印度有些作家断言,以印度在精神性灵方面的博大精深来抵补西方工艺学的优势绰绰有余。新的东西和固有的比较起来,往往被认为是野蛮的。新生的纪元在精神的价值上,往往比即将逝去的纪元似乎显得逊色。
November 27, 2022
根据对象的相对地位来决定拿什么态度相处,而没有一个普遍适用的原则,这只有在一个封闭的社会里才有可能。在一个封闭的有限的圈子里,每个人都认识其他的人,没有什么陌生人闯进来,所以按彼此的相对地位来相处的原则实行起来并没有什么困难。但如果周围有许多陌生人,按这种原则处世的人便会不知所措。当接到一个号码陌生的电话时,一时弄不清对方的真实身份,自己的态度就失去了参考坐标。有时先用傲慢的语气对答,稍后发现对方是自己的首长,立刻前倨而后恭。所以在一个向外界开放的社会里,因人而异的处世原则就不再普遍可行。
从表面上看,在现代最开放、与外界联系最多的社会里,因人而异的处世态度在企业和团体内仍起主导作用。那里下级必须服从上级。而且由于工业生产的要求,这种概念和自然经济社会相比,甚至强化到了一种不近情理的程度。然而在工业社会里服从是一种组织原则而不是伦理规范。下级必须服从上级,工人必须服从工艺要求,否则就会招致经济上的损失。由此可见工业组织中的服从,其最终考虑的是经济利益,而不是维持社会秩序。
在商品经济发达的社会中,维持社会秩序的恰好是协商而不是顺从。不过,无论是在自然经济还是商品经济中,服从只有在一个互相熟悉的小圈子里才行得通,这一点是没有区别的。在一个互相熟悉的小范围内生活,对人的态度依对方的相对地位而定,这造成了人们一种讲面子的社会心理。人要在一个小的社团里受人尊敬,首先要建立一个体面的形象,这种心理部分地解释了何以在我国比较封闭的边远地区,群众习惯于大操大办婚丧喜事,因为这是难得的挣得体面的机会。
由于在自然经济中人的生活来源很少依赖交换,人们生活在一个互相熟悉的圈子里,所以顺从作为一种道德规范才可能行得通,而且能一代一代相传下去,成为一种传统观念。正如鲁迅所说:他们以为父对于子,有绝对的权力和威严;若是老子说话,当然无所不可,儿子有话,却在未说之前早已错了。