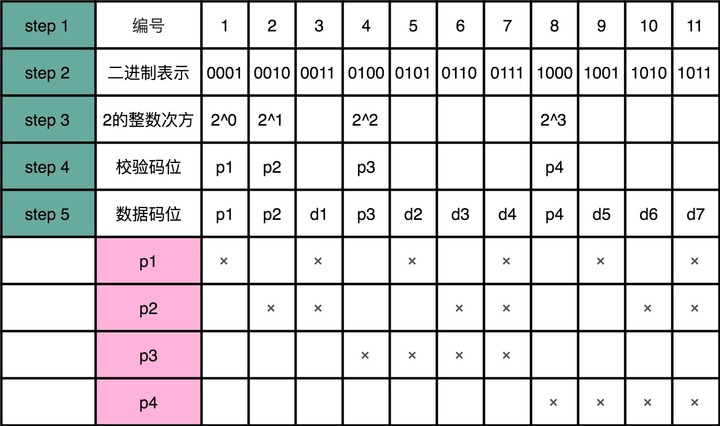
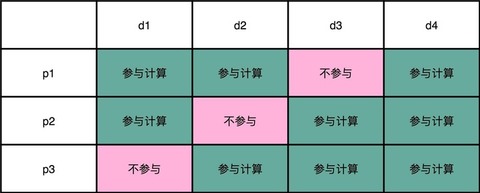
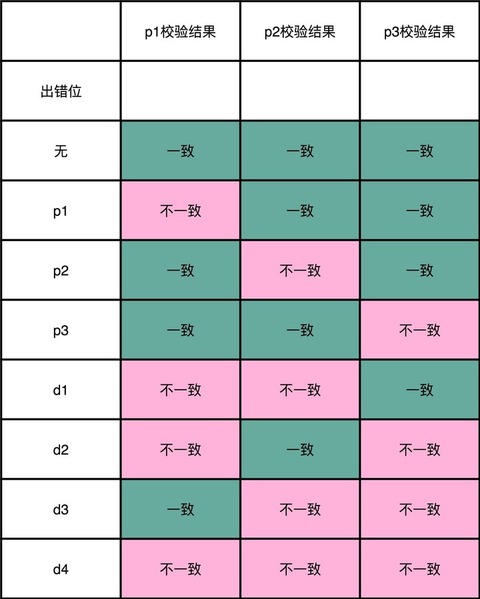
Content #
帕累托改进是说,一种经济行为或经济政策,如果没有任何一个人受损,而至少有一个人受益,这就是帕累托改进。这个概念有非凡的重要性。在平等自愿基础上的商品交换就是帕累托改进,整个市场经济就是建立在此基础之上的。不断进行帕累托改进的结果就是全社会的财富增加。所以商品经济能够使人民生活改善,物质享受增进。不过在经济学里应用的帕累托改进只限于可交换的商品或财富。因为商品和财富是可以客观地用价格来度量的。如果一种政策使少数人受损,多数人受益,只要将多数人所受的利益分一部分给受损的少数人,本来不是帕累托改进的,也可以变成帕累托改进。但条件是损益可以量化比较,少数人得到的补偿应不低于他们受到的损失。
现在我们来讨论如何在不需要牺牲任何一个人的快乐的条件下,至少有一个人增加快乐的方法,也就是快乐的帕累托改进。
孔子说:君子成人之美。这不需要你付出什么,只要不跟人捣乱,或者顺水推舟,顶多出一把小力,帮助别人做成一件好事。自己没有损失,而帮助了别人实现自己的希望,当然使得全社会的快乐总量有所增加。
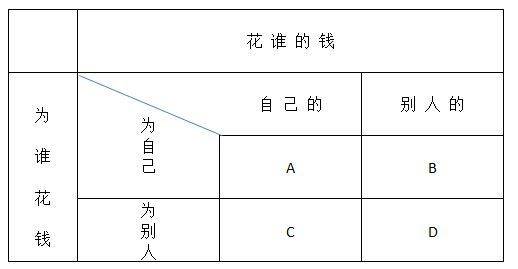 图中A是用自己的钱为自己花,比如在超级市场为自己买东西,既要省钱又要买得合算。这是最有效的花钱方式。B是为自己花别人的钱,比如可报销的用餐,你不会想着节约,但是会尽量使自己满意。C是为了别人花自己的钱。比如给朋友买礼物,你会想着节省但朋友喜欢什么你只能猜想,很可能花钱买了一个别人并不喜欢的礼物。D是你为别人花别人的钱。比如你负责审批一笔报销,你既不会想着节约,也不会考虑钱花得有没有效果,只要符合规定的报销制度就行。弗里德曼用这个矩阵说明“福利国家的谬论”,意思是说,花钱最好是自己花自己的钱。由国家来安排百姓的福利必然是低效的。他反对先征税,再由国家安排百姓的福利,比如教育、医疗、住房等。
图中A是用自己的钱为自己花,比如在超级市场为自己买东西,既要省钱又要买得合算。这是最有效的花钱方式。B是为自己花别人的钱,比如可报销的用餐,你不会想着节约,但是会尽量使自己满意。C是为了别人花自己的钱。比如给朋友买礼物,你会想着节省但朋友喜欢什么你只能猜想,很可能花钱买了一个别人并不喜欢的礼物。D是你为别人花别人的钱。比如你负责审批一笔报销,你既不会想着节约,也不会考虑钱花得有没有效果,只要符合规定的报销制度就行。弗里德曼用这个矩阵说明“福利国家的谬论”,意思是说,花钱最好是自己花自己的钱。由国家来安排百姓的福利必然是低效的。他反对先征税,再由国家安排百姓的福利,比如教育、医疗、住房等。