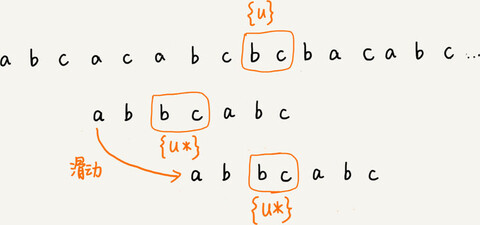Content
#
#include<cstring>中的memset是按字节填充的。例如,int占4字节,因此memset(a,0x3f,sizeof(a))按字节填充相当于将0x3f3f3f3f赋值给数组
a[]的每个元素。memset经常用来初始化一个int型数组为0、-1,或者最大值、最小值,也可以初始化一个bool型数组为true(1)或false(0)。
不可以用memset初始化一个int型数组为1,因为memset(a,1,sizeof(a))相当于将每个元素都赋值为0000 0001 0000 0001 0000 0001 0000 0001,即将0000
0001分别填充到4字节中。布尔数组可以赋值为true,是因为布尔数组中的每个元素都只占1字节。
memset(a,0,sizeof(a)); //初始化为0
memset(a,-1,sizeof(a));//初始化为-1
memset(a,0x3f,sizeof(a));//初始化为最大值0x3f3f3f3f
memset(a,0xcf,sizeof(a));//初始化为最小值0xcfcfcfcf
需要注意的是,动态数组或数组作为函数参数时,不可以用sizeof(a)测量数组空间,因为这样只能测量到首地址的空间。可以用
memset(a,0x3f,n×sizeof(int))的方法处理,或者用fill函数填充。
如果用memset(a,0x3f,sizeof(a))填充double类型的数组,则经常会得到一个连
1都不到的小数。double类型的数组填充极值时需要用fill(a,a+n,0x3f3f3f3f)。
尽管0x7fffffff是32-bit int的最大值,但是一般不使用该值初始化最大值,因为0x7fffffff不能满足“无穷大加一个有穷的数依然是无穷大”,它会变成一个很小的负数。0x3f3f3f3f的十进制是1061109567,也就是10^9级别的(和
0x7fffffff在一个数量级),而一般情况下的数据都是小于10^9的,所以它可以作为无穷大使用而不至于出现数据大于无穷大的情形。另一方面,由于一般的数据都不会大于10^9,所以当把无穷大加上一个数据时,它并不会溢出(这就满足了“无穷大加一个有穷的数依然是无穷大”)。事实上,
0x3f3f3f3f+0x3f3f3f3f=2122219134,这非常大但却没有超过32-bit int的表示范围,所以0x3f3f3f3f还满足了“无穷大加无穷大还是无穷大”的需求。
From
#
Links
#

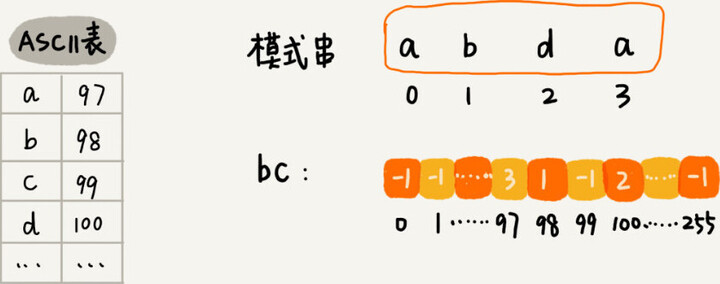
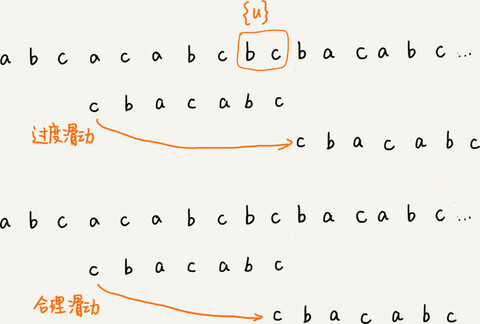
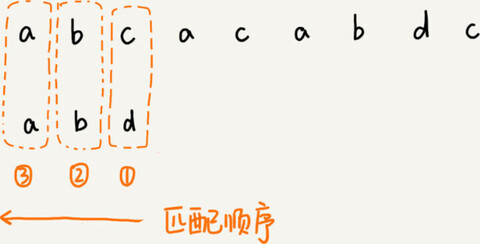
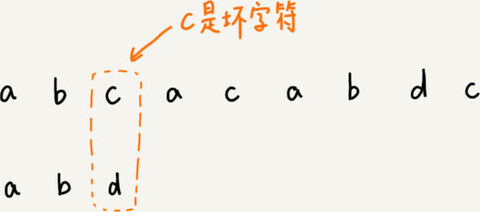
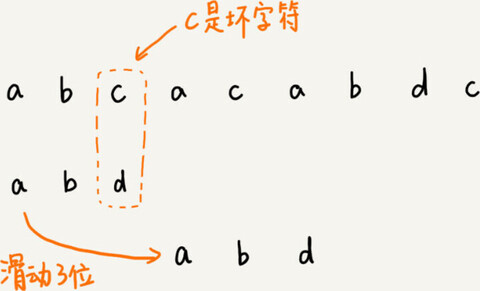
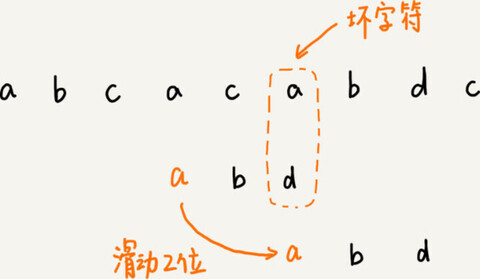
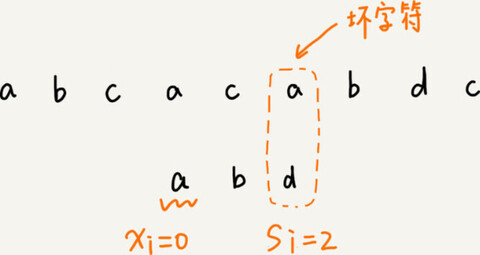
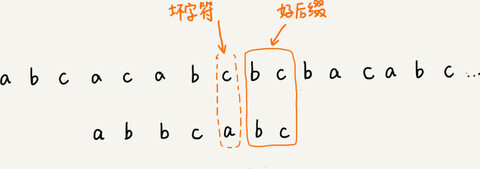 把已经匹配的 bc 叫作好后缀,记作{u}。
把已经匹配的 bc 叫作好后缀,记作{u}。