Content #
与人类相比,深度学习想要充分发挥作用,离不开海量的相关数据、单一领域的应用场景以及明确的目标函数,这三项缺一不可,如果缺少其中任何一项,深度学习将无用武之地。
如果数据太少,AI算法就没有足够多的样本去洞察数据背后的模糊特征之间的有意义的关联;如果问题涉及多个领域,AI算法就无法周全考虑不同领域之间的关联,也无法获得足够的数据来覆盖跨领域多因素排列组合的所有可能性;如果目标函数太过宽泛,AI算法就缺乏明确的方向,以至于很难进一步优化模型的性能。
From #
AI未来进行式
 April 4, 2023
April 2, 2023
April 2, 2023
April 4, 2023
April 2, 2023
April 2, 2023
XDP(eXpress Data Path),则是 Linux 内核提供的一种高性能网络数据路径。它允许网络包,在进入内核协议栈之前,就进行处理,也可以带来更高的性能。 XDP 底层跟我们之前用到的 bcc-tools 一样,都是基于 Linux 内核的 eBPF 机制实现的。
XDP 的原理如下图所示:
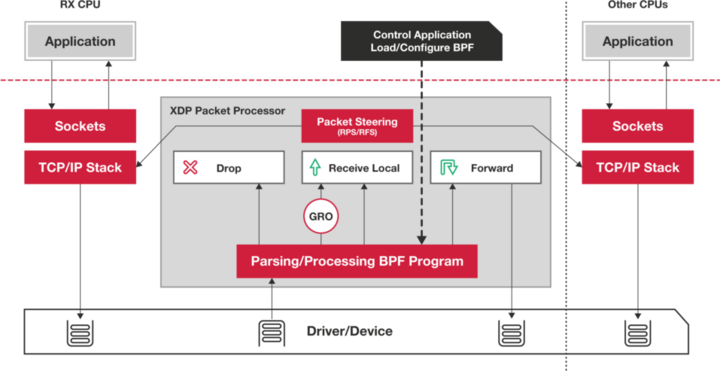
XDP 对内核的要求比较高,需要的是 Linux 4.8 以上版本,并且它也不提供缓存队列。基于 XDP 的应用程序通常是专用的网络应用,常见的有 IDS(入侵检测系统)、DDoS 防御、 cilium 容器网络插件等。
April 2, 2023
DPDK,是用户态网络的标准。它跳过内核协议栈,直接由用户态进程通过轮询的方式,来处理网络接收。
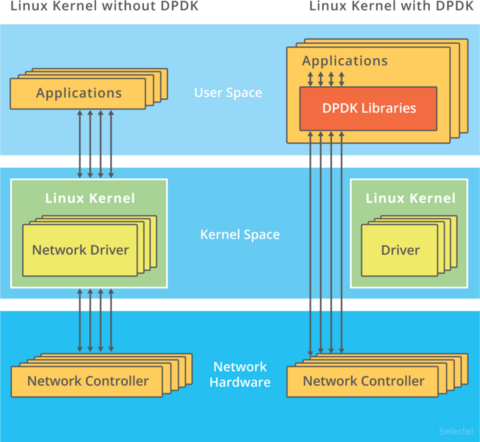
说起轮询,你肯定会下意识认为它是低效的象征,但是进一步反问下自己,它的低效主要体现在哪里呢?是查询时间明显多于实际工作时间的情况下吧!那么,换个角度来想,如果每时每刻都有新的网络包需要处理,轮询的优势就很明显了。比如:
在 PPS 非常高的场景中,查询时间比实际工作时间少了很多,绝大部分时间都在处理网络包;
而跳过内核协议栈后,就省去了繁杂的硬中断、软中断再到 Linux 网络协议栈逐层处理的过程,应用程序可以针对应用的实际场景,有针对性地优化网络包的处理逻辑,而不需要关注所有的细节。
此外,DPDK 还通过大页、CPU 绑定、内存对齐、流水线并发等多种机制,优化网络包的处理效率。
https://blog.selectel.com/introduction-dpdk-architecture-principles/
April 1, 2023
March 31, 2023
March 31, 2023
网络收发的字节数、包数、错误数以及丢包情况,特别是 TX 和 RX 部分的 errors、dropped、overruns、carrier 以及 collisions 等指标不为 0 时,通常表示出现了网络 I/O 问题。其中:
errors 表示发生错误的数据包数,比如校验错误、帧同步错误等;
dropped 表示丢弃的数据包数,即数据包已经收到了 Ring Buffer,但因为内存不足等原因丢包;
overruns 表示超限数据包数,即网络 I/O 速度过快,导致 Ring Buffer 中的数据包来不及处理(队列满)而导致的丢包;
carrier 表示发生 carrirer 错误的数据包数,比如双工模式不匹配、物理电缆出现问题等;
collisions 表示碰撞数据包数。
March 31, 2023
带宽,表示链路的最大传输速率,单位通常为 b/s (比特 / 秒)。
吞吐量,表示单位时间内成功传输的数据量,单位通常为 b/s(比特 / 秒)或者 B/s(字节 / 秒)。吞吐量受带宽限制,而吞吐量 / 带宽,也就是该网络的使用率。
延时,表示从网络请求发出后,一直到收到远端响应,所需要的时间延迟。在不同场景中,这一指标可能会有不同含义。比如,它可以表示,建立连接需要的时间(比如 TCP 握手延时),或一个数据包往返所需的时间(比如 RTT)。
PPS,是 Packet Per Second(包 / 秒)的缩写,表示以网络包为单位的传输速率。PPS 通常用来评估网络的转发能力,比如硬件交换机,通常可以达到线性转发(即 PPS 可以达到或者接近理论最大值)。而基于 Linux 服务器的转发,则容易受网络包大小的影响。
March 30, 2023
HighScore House始于一个简单的应用程序:家长能通过它罗列出希望孩子们完成的家务活及挑战,为其打分;而孩子们则能完成任务,获取分值,并将这些虚拟的分值兑换成他们想要的奖励。
当HighScore House发布他们的最小可行化产品时,有几百个志愿家庭愿意参与内部测试。当时,几位创始人摸着石头过河,为最小可行化产品的成功下了这样的定义:家长和孩子每周每人使用产品至少四次。达到这一阈值的家庭称为“活跃用户”。这个成功的标准定得很高,但清晰扼要。
然而,一个多月过去了,活跃家庭的百分比他们预期目标的要低。几位创始人很失望,但决心继续试验下去,努力提高用户的参与度:
❑ 他们调整了注册流程(使之更明了、更富教育软件特色以吸引高质量用户;同时,使用户更容易上手);❑ 他们给家长发送每日邮件提醒;❑ 他们根据孩子在系统中所触发的行动,给家长发送事务性邮件。
虽然每一个新的尝试都为产品带来了一些改善,但都没能充分地推动产品使创始团队宣称:产品成功了。
这时,创始人之一、时任CEO的凯尔·希曼做出了一个关键的决定:他拿起了电话。凯尔与几十位家长通了话,从那些已注册却并不活跃的家长们开始。首先,他打给那些完全抛弃了High Score House的家长(所谓的流失用户),了解到很多人离开的原因是HighScore House解决的并不是他们的紧要问题。这没什么大不了的,创始团队从未假设过这款产品适用于所有家长——对于一个创业产品而言,“所有家长”这个市场显然定义得过大了。凯尔将精力放在寻找家长中的一个子市场,一个能认同HighScore House价值的家长人群,方便他聚焦于更加细分的领域。
接下来,凯尔给那些正在使用HighScore House,但不够活跃的家庭去了电话。他们中的很多家长都对产品给予了正面评价:“我们在使用HighScore House。它是一个很棒的产品。因为有了它,我的孩子终于能够坚持每天叠被子了!”
从这些家长处得到的回应令创始团队十分惊喜。尽管他们中的大多数每周仅使用 HighScore House一到两次,但这已经足以使他们认可产品的价值了。从这些电话访谈中,凯尔学到了细分市场,了解了产品对哪类家庭更具吸引力。他开始认识到,他们一开始设定的划分活跃/非活跃用户的准绳实际上并不能很好地反映实际用户的参与度。
这并不是说HighScore House团队不该在一开始提出这样一条准绳。如果没有那个设想,他们也就不会为了修正准绳而学到这些东西,凯尔也不可能拿起电话。然而现在,他真正地理解了他的用户,定量数据与定性数据相结合是他成功的关键。
在这次经验的基础上,HighScore House团队重新定义了区分“活跃”和“非活跃”用户的阈值,用以更好地反映现有用户的行为。在这个案例中,调整关键指标对HighScore House团队而言是可行的,因为他们真正理解此举的原因,并且能够应对随之而来的变化。
总结
❑ HighScore House团队过早、过于激进地划了一条用于区分用户活跃度的准绳——一个不可能完成的任务;❑ HighScore House团队通过快速试验提高了活跃用户的数量,但是活跃用户的百分比总体没有很大提高;❑ 他们开始明智地拿起电话联系客户,发现那些低于假设“活跃度”阈值的用户能够从产品中获取很大价值。
数据分析启示
首先,了解你的客户。没有比直接与客户和用户对话更有效的手段了。任你得到的数据再多,它们也解释不了事情发生的原因。现在就拿起电话拨通一位客户的号码,即使是一位参与度不高的用户,也会对你很有帮助。
其次,尽早做出一些假设并定下你认为可称为“成功”的目标,但切忌在试验中迷失自己。如果需要,可以降低指标的阈值,但并不是为了制造达到这个阈值的假象:这样只会自欺欺人。使用定性数据来理解你为用户创造的价值是什么。只有调整后的阈值或准绳可以更好地反映(某个细分市场中的)用户使用产品的习惯,调整才是合理的、必要的。
March 30, 2023
“朋友圈”的构想很简单:它允许你将Facebook好友分类到不同的圈子,以便进行指定圈子的分享。2007年9月,在Facebook发布开发者平台后不久,麦克·格林菲尔德等人共同创办了这家公司。这个时机近乎完美:Facebook正在成为一个极速获取用户的病毒式开放平台,同时也成就了很多创业公司。在这之前,从没有一个平台像Facebook一样既拥有巨大的用户数量,又如此开放(当时Facebook已有约5000万用户)。
到2008年中期,“朋友圈”已经拥有1000万用户。麦克视用户增长为首要使命,他说“这就像是在抢地盘”,“朋友圈”显然已在病毒式传播。然而,一个问题出现了:只有很少的用户在真正地使用这个产品。
麦克发现,只有不到20%的圈子在创建后有过活动的迹象。“1000万的注册用户每月能为我们带来几百万的独立访客数,可我们深知这个成绩对于一个通用社交网络来说还不够好。一旦收费,变现效果可能不佳。”
麦克开始探寻背后的原因。
他首先查看了用户数据库,想搞清楚用户们都做了些什么。当时,公司还没有一套可以做深度数据分析的系统,但这并不妨碍麦克进行一些探索性的分析。最后他发现,有一个用户群体在其他群体活跃度较低的情况下,撑起了整个产品的用户参与度——这就是妈妈群体。以下是他的发现:
❑ 妈妈群体之间所发的站内信平均比其他站内信长50%;❑ 她们在帖子中附图片的概率比其他人群高115%;❑ 她们在Facebook上进入多回合深入对话的概率比其他人群高110%;❑ 她们的好友在被邀请入应用后,成为高参与度用户的概率比其他用户高50%;❑ 她们点击Facebook提醒的概率比其他人群高75%;❑ 她们点击Facebook新鲜事内容的概率比其他人群高180%;❑ 她们接受应用邀请的概率比其他人群高60%。
这些数字实在是太有说服力了。于是,在2008年6月,麦克和他的团队完全调整了产品重心,作出了关键转型。2008年10月,他们在Facebook上发布了“妈妈圈”社交产品。
起初,由于产品的大转型,各项数据都有所下降。然而,到2009年底,“妈妈圈”的社区用户数已增至450万;与那些在转型中丢掉的用户不同,这些都是些参与度很高的活跃用户。在这之后,Facebook开始限制站内应用通过其平台进行病毒式传播,过分依托Facebook推广的“妈妈圈”也是几经沉浮。最终,它摆脱 Facebook,成立了一个独立的网站,并于2012年初被Sugar公司收购。
总结
❑“朋友圈”这个社交图谱应用出现在了正确的时间(Facebook刚启动开放平台时)和正确的地点(Facebook站内应用),只是找错了市场。❑ 通过分析用户的行为模式和理想行为的分布,发掘高活跃度用户的共同点,公司找到了与自身产品相匹配的市场。❑ 在找准目标以后,不遗余力地聚焦,直至更改产品名称。要么坚定地转型,要么缴械投降,准备好放弃部分已有的成就,这就是“妈妈圈”成功的秘诀。
数据分析启示
麦克成功创办“妈妈圈”的关键在于,他有能力深入挖掘数据,寻找有意义的用户行为模式和机遇。麦克发现了一个“他不知道自己不知道”的事实,这促使他下了大赌注,听起来骇人却颇显胆识(放弃面向所有人的“朋友圈”转而深耕于一个特定的人群/市场)。毫无疑问,这是一次赌博,但它以调研数据为基础。
想要让一款社区产品极速启动就需要相当高的用户参与度。不温不火的用户表现无法提供足够的“逃逸速度”,让你的产品冲上云霄。在这种情况下,更好的做法是:在一个更小的、更容易触及的目标市场中培养更多具有黏性的高活跃度用户。病毒式传播需要专注。