Content
#
我们的房价其实和我们的身高是不一样的,它不是我们想象当中的正态分布,而是我下面提到的拉普拉斯分布。
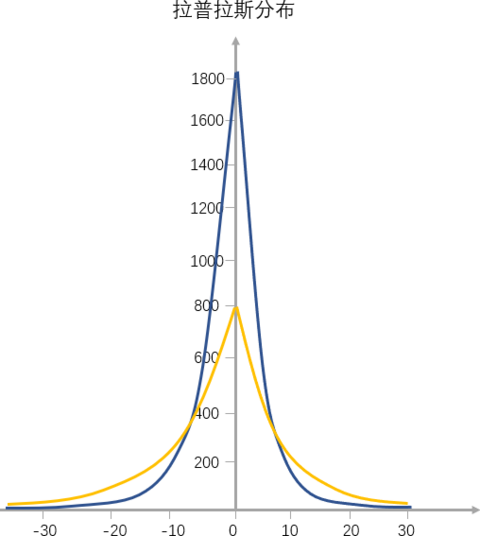
拉普拉斯分布是一个“凸”字形的塔尖儿曲线,从左到右,斜率先缓慢增大再快速增大,到达最高点后变为负值继续先快速减小,最后再缓慢地减小,所以有点像“往里边凹陷的金字塔”。
对比正态分布的概率密度函数图像,我们可以看到拉普拉斯分布图像是尖峰厚尾的,塔尖上的那些,就是我们看到的稀缺资源。比如拿全球顶尖程序员的薪资(塔尖对应的横坐标值是均值)来说,全球顶尖的程序员年薪是 100 万美元,但这部分群体可能只占全球城市人口的 1%,程序员中的人数不足 10%。但是,
90% 的资源其实都在他们的身上,够刺激吧。
那我们怎样去理解这个拉普拉斯分布呢?它经常用在金融领域,尤其是衡量股票收益的时候。起初我们认为股票收益率是服从正态分布,但是由于股票价格波动与时间变化有关,有波动聚集性,最后实际股票的收益率都是符合拉普拉斯分布的,也就是赚大钱的日子其实特别集中,余下的都是赚小钱的日子。
现在随着市场和互联网的发展,信息越来越透明,我们相关的数据分布其实变化还是挺大的。
比如说在改革开放之前信息不对称,资源也相对没有那么聚集,人们拿到的工资是一个正态分布的。但是到了现在,就我们程序员的工资来说,一个顶尖的程序员和普通的程序员的工资收入可能会差十倍都不止,这就会导致更厚的尾部和更高的峰度。
而全国的城市房价分布、一个城市当中的小区房价分布现在也是符合拉普拉斯分布的。因为在信息透明和市场竞争的情况下,工资、房价、股票都会符合一个特点:越塔尖的个体越具有资源吸附能力。那么在整体资源恒定的情况下,这已经不是一个简单的符合随机分布的市场了,简单来讲,“大势”变了。
所以当你在做数据分析的时候,一定得先考虑一下,原有的数据分布模型是否还适用于现有的市场情况?
准确把握住数据分布这个大势,我们才能够做出更为正确的决策。就拿买房这件事来说吧,买房是一个我们基本都绕不开的话题,在你买房前,你可以先判断一下你要买的房屋的房价在这座城市里是正态分布还是拉普拉斯分布。
也就是说你可以去评估一下,你所在城市资源是否比较平均?会不会出现聚集效应?如果你认真用这两个分布去判断一下,你会发现如果你所在的城市是三四线城市,那么房价的分布大概率会呈正态分布。那么在这种情况下你要投资买房就可以选择价格在曲线腰部的房子,这种房子的房价将来涨跌以及抗风险性都比较适中。
而如果你准备买大城市里的房子,情况就不一样了。因为对于一线城市的房价而言,大概率是呈拉普拉斯分布的,这也就意味着越贵的房子周边资源越好,进而这些房子将来增值空间越大。那我们买房子的时候就应该买资源最好的最贵的房子,未来的收获也最大(当然,如果最贵的已经天价了,那么我们可以退而求其次)。
反之,当你看到一些铺面房非常便宜的时候,你要留个心眼了:是不是这些铺面房处于拉普拉斯分布的最两侧?如果是,那么这些铺面房不但增值空间小,将来还有可能买了亏本的风险。所以,只有了解整体市场的分布我们才能够更好地把握市场大势,顺势而为。
Viewpoints
#
From
#
06 | 数据分布:房子应该是买贵的还是买便宜的?
Links
#