Content
#
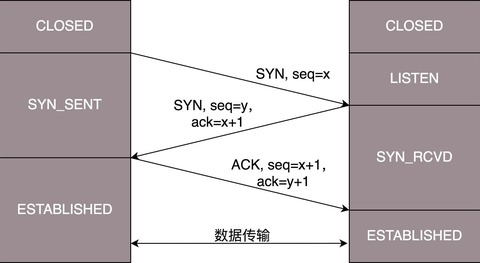
TCP SYN Cookies 也是一种专门防御 SYN Flood 攻击的方法。SYN Cookies 基于连接信息(包括源地址、源端口、目的地址、目的端口等)以及一个加密种子(如系统启动时间),计算出一个哈希值(SHA1),这个哈希值称为 cookie。
然后,这个 cookie 就被用作序列号,来应答 SYN+ACK 包,并释放连接状态。当客户端发送完三次握手的最后一次 ACK 后,服务器就会再次计算这个哈希值,确认是上次返回的 SYN+ACK 的返回包,才会进入 TCP 的连接状态。
因而,开启 SYN Cookies 后,就不需要维护半开连接状态了,进而也就没有了半连接数的限制。内核选项 net.ipv4.tcp_max_syn_backlog 也就无效了。
你可以通过下面的命令,开启 TCP SYN Cookies:
$ sysctl -w net.ipv4.tcp_syncookies=1
net.ipv4.tcp_syncookies = 1
When the connection queue begins to get full, the system starts
responding to SYN requests with SYN cookies rather than SYN-ACKs, and
it frees the queue slot. Thus, the queue never fills completely. The
cookie has a short timeout; the client must respond to it within a
short period before the serving host will respond with the expected
SYN-ACK. The cookie is a sequence number that is generated based on
the original sequence number in the SYN, the source and destination
addresses and ports, and a secret value. If the response to the cookie
matches the result of the hashing algorithm, the server is reasonably
well assured that the SYN is valid.
...