Content #
“Elf32_Shdr”又被称为段描述符(Section Descriptor)。 Elf32_Shdr被定义在“/usr/include/elf.h”。
typedef struct
{
Elf32_Word sh_name;
Elf32_Word sh_type;
Elf32_Word sh_flags;
Elf32_Addr sh_addr; /* Section virtual addr at execution */
Elf32_Off sh_offset; /* Section file offset */
Elf32_Word sh_size; /* Section size in bytes */
Elf32_Word sh_link;
Elf32_Word sh_info;
Elf32_Word sh_addralign;
Elf32_Word sh_entsize; /* Entry size if section holds table */
} Elf32_Shdr;
sh_type #
#define SHT_PROGBITS 1 /* Program data */
#define SHT_SYMTAB 2 /* Symbol table */
#define SHT_STRTAB 3 /* String table */
#define SHT_RELA 4 /* Relocation entries with addends */
#define SHT_HASH 5 /* Symbol hash table */
#define SHT_DYNAMIC 6 /* Dynamic linking information */
#define SHT_NOTE 7 /* Notes */
#define SHT_NOBITS 8 /* Program space with no data (bss) */
#define SHT_REL 9 /* Relocation entries, no addends */
#define SHT_SHLIB 10 /* Reserved */
#define SHT_DYNSYM 11 /* Dynamic linker symbol table */
#define SHT_INIT_ARRAY 14 /* Array of constructors */
#define SHT_FINI_ARRAY 15 /* Array of destructors */
#define SHT_PREINIT_ARRAY 16 /* Array of pre-constructors */
#define SHT_GROUP 17 /* Section group */
#define SHT_SYMTAB_SHNDX 18 /* Extended section indices */
sh_flag #
#define SHF_WRITE (1 << 0) /* Writable */
#define SHF_ALLOC (1 << 1) /* Occupies memory during execution */
#define SHF_EXECINSTR (1 << 2) /* Executable */
#define SHF_MERGE (1 << 4) /* Might be merged */
#define SHF_STRINGS (1 << 5) /* Contains nul-terminated strings */
#define SHF_INFO_LINK (1 << 6) /* `sh_info' contains SHT index */
#define SHF_LINK_ORDER (1 << 7) /* Preserve order after combining */
#define SHF_OS_NONCONFORMING (1 << 8) /* Non-standard OS specific handling required */
#define SHF_GROUP (1 << 9) /* Section is member of a group. */
#define SHF_TLS (1 << 10) /* Section hold thread-local data. */
#define SHF_COMPRESSED (1 << 11) /* Section with compressed data. */
...
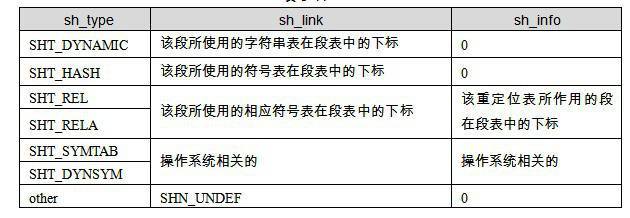
sh_link, sh_info #
段的链接信息(sh_link、sh_info) 如果段的类型是与链接相关的(不论是动态链接或静态链接),比如重定位表、符号表等,那么sh_link和sh_info这两个成员所包含的意义如下表所示。对于其他类型的段,这两个成员没有意义。