Content #
glibc的程序入口为_start(这个入口是由ld链接器默认的链接脚本所指定的,我们也可以通过相关参数设定自己的入口)。_start由汇编实现,并且和平台相关,下面可以单独看i386的_start实现:
libc\sysdeps\i386\elf\Start.S:
_start:
xorl %ebp, %ebp
popl %esi
movl %esp, %ecx
pushl %esp
pushl %edx
pushl $__libc_csu_fini
pushl $__libc_csu_init
pushl %ecx
pushl %esi
pushl main
call __libc_start_main
hlt
_start函数最终调用了名为__lib_start_main的函数。
xor %ebp, %ebp
这其实是让ebp寄存器清零。ebp设为0正好可以体现出这个最外层函数的尊贵地位。
pop %esi
mov %esp, %ecx
在调用_start前,装载器会把用户的参数和环境变量压入栈中,按照其压栈的方法,实际上栈顶的元素是argc,而接着其下就是argv和环境变量的数组。下图为此时的栈布局,其中虚线箭头是执行pop %esi之前的栈顶(%esp),而实线箭头是执行之后的栈顶(%esp)。
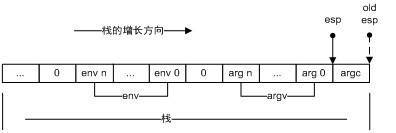 pop %esi将argc存入了esi,而mov %esp、%ecx将栈顶地址(此时就是argv和环境变量(env)数组的起始地址)传给%ecx。现在%esi指向argc,%ecx指向argv
及环境变量数组。
pop %esi将argc存入了esi,而mov %esp、%ecx将栈顶地址(此时就是argv和环境变量(env)数组的起始地址)传给%ecx。现在%esi指向argc,%ecx指向argv
及环境变量数组。
综合以上分析,我们可以把_start改写为一段更具有可读性的伪代码:
void _start()
{
%ebp = 0;
int argc = pop from stack
char** argv = top of stack;
__libc_start_main( main, argc, argv, __libc_csu_init, __libc_csu_fini,
edx, top of stack );
}
其中argv除了指向参数表外,还隐含紧接着环境变量表。这个环境变量表要在__libc_start_main里从argv内提取出来。
...