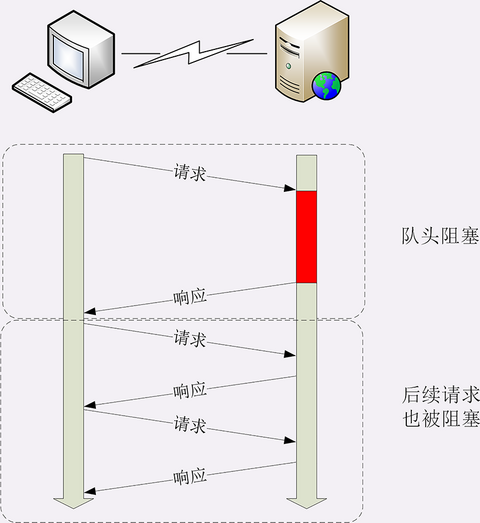
Content #
当政府权力渗入高校治理的环节,且大学坚持知识生产和育人使命时,现实中的大学生活就远非市场逻辑所能理解的了,而是充满了与市场理性无关的许多其他内容。可以这么说:从新生入学的那天起,直到他/她有一天忽然意识到自己快要毕业了,这一过程的丰富性甚至可能让他/她短暂地忽视就业市场的竞争规则。
事实上,在我国一流大学的校园里,占据学生们大量时间和精力的各类课内外活动,诸如讲座、社团、党校、学生会、社会实践、志愿服务、学术科创竞赛等等,大都与就业准备并无显然的联系。生机勃勃的校园里充斥着一张张令人炫目的活动海报,看似杂乱无章,实则各有其理:讲座主要由院系举办,目的是增强学术交流、拓宽师生的知识面;以兴趣爱好为基础组建的各类学生社团则有助于丰富校园生活、促进兴趣和特长发展;党团组织活动是吸纳、培养党员和发扬党的先进性的抓手;学术科创项目意在激发学生的科研潜力和创新能力;各类社会调研、实践和志愿服务活动则扮演着落实思想政治教育、培养社会主义核心价值观的第二课堂角色……学校表彰奖励优秀学生的评价体系很大程度上基于学业水平、品德和校园活动参与度,与市场上对就业能力的评估标准关联度不大。学校提供的针对毕业生就业的政策也以全局的国家利益为先,对学生的价值感召——例如那句耳熟能详的“到祖国最需要的地方去”——往往带着浓厚的集体主义的家国情怀,而非谋求个人利益最大化的市场逻辑。
总之,市场化在大学内外部发生程度的不同,使得“成为好学生”和“找着好工作”对应着不同的游戏规则,这无疑加大了学生安排大学生活的难度。当大学生懵懵懂懂地踏入名校校园,很可能会发现其间的生活像极了一个被精心布局的异彩纷呈的迷宫:并不存在一条“主路”或某种标准走法——似乎每一天的过法都有许多种可能,每个人在路口处需要不断地做选择,每一条小路(例如科研、学生会、社团等)都各有乾坤,且大多与迷宫外的世界保持着一定的距离。他们在各个小路之中穿行探索,一边选择自己的路线,一边在路途上收集着有价值的筹码(成绩、经历、奖项等)。他们与其他探索者之间是一种心照不宣的竞争关系,因为筹码的数量是有限的;当他们到达迷宫出口的时候,他们需要将口袋里的筹码拿出来,用它们来兑换成下一个旅程的入场券。不过,对不同社会出身的探索者来说,这个迷宫的神秘度是不同的。有人对里面的布局相当了解,有人半知半解,而有人只能通过道听途说略知一二。尤其关键的是:并不是所有人都很清楚当中的游戏规则,譬如迷宫的尽头究竟有哪几个出口,而每个出口处有用的筹码又有什么不同。
From #
金榜题名之后
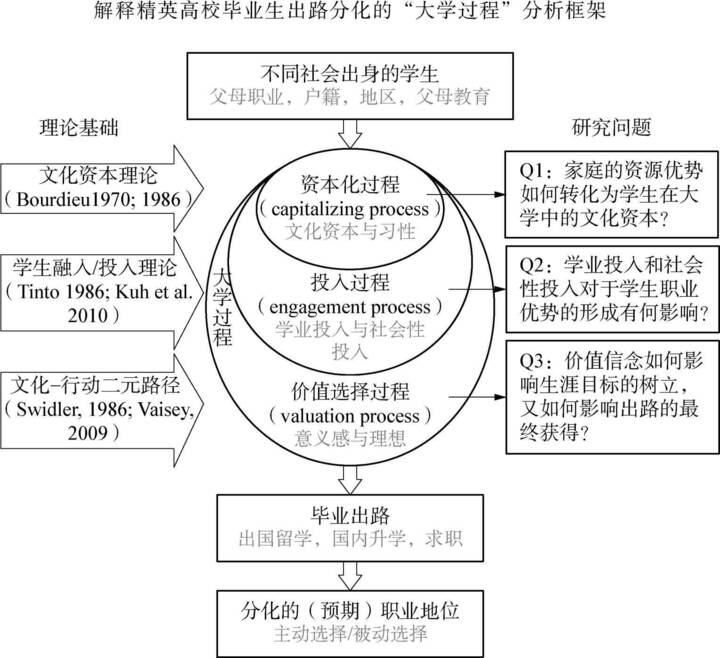 “资本化过程”(capitalizing process)来源于
“资本化过程”(capitalizing process)来源于