
Content #
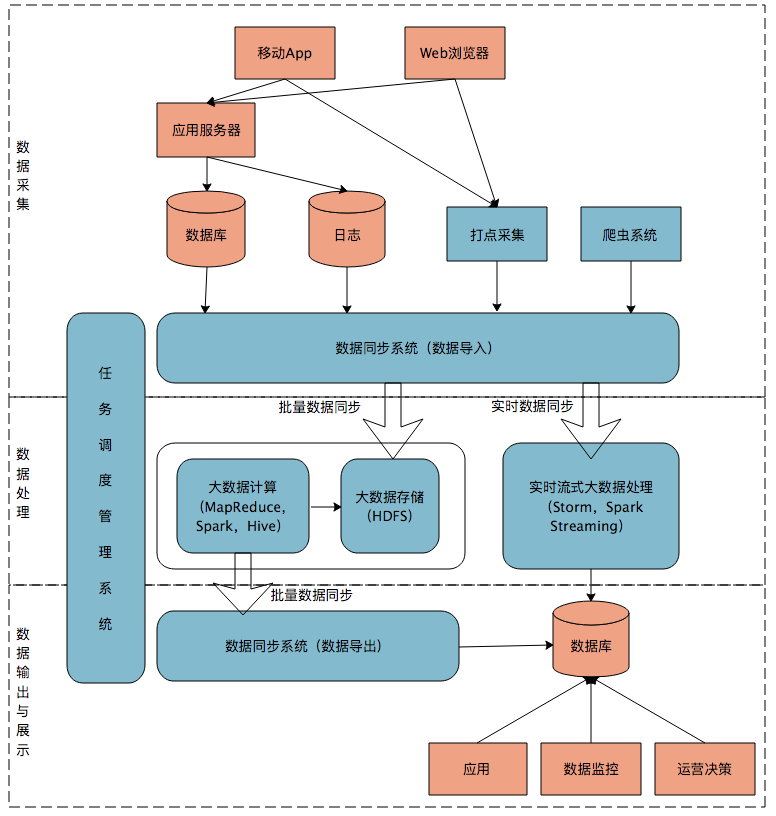
在这张架构图中,大数据平台里面向用户的在线业务处理组件用褐色标示出来,这部分是属于互联网在线应用的部分,其他蓝色的部分属于大数据相关组件,使用开源大数据产品或者自己开发相关大数据组件。
你可以看到,大数据平台由上到下,可分为三个部分:数据采集、数据处理、数据输出与展示。
数据采集
将应用程序产生的数据和日志等同步到大数据系统中,由于数据源不同,这里的数据同步系统实际上是多个相关系统的组合。数据库同步通常用 Sqoop,日志同步可以选择 Flume,打点采集的数据经过格式化转换后通过 Kafka 等消息队列进行传递。
不同的数据源产生的数据质量可能差别很大,数据库中的数据也许可以直接导入大数据系统就可以使用了,而日志和爬虫产生的数据就需要进行大量的清洗、转化处理才能有效使用。
数据处理
这部分是大数据存储与计算的核心,数据同步系统导入的数据存储在 HDFS。MapReduce、Hive、Spark 等计算任务读取 HDFS 上的数据进行计算,再将计算结果写入 HDFS。
MapReduce、Hive、Spark 等进行的计算处理被称作是离线计算,HDFS 存储的数据被称为离线数据。在大数据系统上进行的离线计算通常针对(某一方面的)全体数据,比如针对历史上所有订单进行商品的关联性挖掘,这时候数据规模非常大,需要较长的运行时间,这类计算就是离线计算。
除了离线计算,还有一些场景,数据规模也比较大,但是要求处理的时间却比较短。比如淘宝要统计每秒产生的订单数,以便进行监控和宣传。这种场景被称为大数据流式计算,通常用 Storm、Spark Steaming 等流式大数据引擎来完成,可以在秒级甚至毫秒级时间内完成计算。
数据输出与展示
前面我说过,大数据计算产生的数据还是写入到 HDFS 中,但应用程序不可能到 HDFS 中读取数据,所以必须要将 HDFS 中的数据导出到数据库中。数据同步导出相对比较容易,计算产生的数据都比较规范,稍作处理就可以用 Sqoop 之类的系统导出到数据库。
这时,应用程序就可以直接访问数据库中的数据,实时展示给用户,比如展示给用户关联推荐的商品。淘宝卖家的量子魔方之类的产品,其数据都来自大数据计算产生。
除了给用户访问提供数据,大数据还需要给运营和决策层提供各种统计报告,这些数据也写入数据库,被相应的后台系统访问。很多运营和管理人员,每天一上班,就是登录后台数据系统,查看前一天的数据报表,看业务是否正常。如果数据正常甚至上升,就可以稍微轻松一点;如果数据下跌,焦躁而忙碌的一天马上就要开始了。
将上面三个部分整合起来的是任务调度管理系统,不同的数据何时开始同步,各种 MapReduce、Spark 任务如何合理调度才能使资源利用最合理、等待的时间又不至于太久,同时临时的重要任务还能够尽快执行,这些都需要任务调度管理系统来完成。
有时候,对分析师和工程师开放的作业提交、进度跟踪、数据查看等功能也集成在这个任务调度管理系统中。
简单的大数据平台任务调度管理系统其实就是一个类似 Crontab 的定时任务系统,按预设时间启动不同的大数据作业脚本。复杂的大数据平台任务调度还要考虑不同作业之间的依赖关系,根据依赖关系的 DAG 图进行作业调度,形成一种类似工作流的调度方式。
对于每个公司的大数据团队,最核心开发、维护的也就是这个系统,大数据平台上的其他系统一般都有成熟的开源软件可以选择,但是作业调度管理会涉及很多个性化的需求,通常需要团队自己开发。开源的大数据调度系统有 Oozie,也可以在此基础进行扩展。