
Content #
所谓定向计数,它指的是只对某些单词进行计数,例如,给定单词列表 list,我们只对文件 wikiOfSpark.txt 当中的“Apache”和“Spark”这两个单词做计数,其他单词我们可以忽略。
import org.apache.spark.rdd.RDD
val rootPath: String = _
val file: String = s"${rootPath}/wikiOfSpark.txt"
// 读取文件内容
val lineRDD: RDD[String] = spark.sparkContext.textFile(file)
// 以行为单位做分词
val wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" "))
// 创建单词列表list
val list: List[String] = List("Apache", "Spark")
// 使用list列表对RDD进行过滤
val cleanWordRDD: RDD[String] = wordRDD.filter(word => list.contains(word))
// 把RDD元素转换为(Key,Value)的形式
val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, 1))
// 按照单词做分组计数
val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)
// 获取计算结果
wordCounts.collect
// Array[(String, Int)] = Array((Apache,34), (Spark,63))
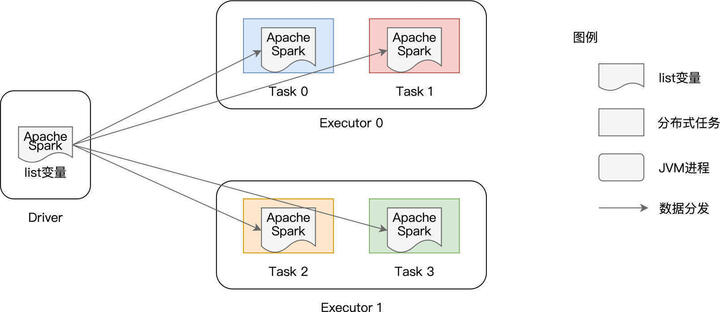
如上图所示,list 变量本身是在 Driver 端创建的,它并不是分布式数据集(如 lineRDD、wordRDD)的一部分。因此,在分布式计算的过程中,Spark 需要把 list 变量分发给每一个分布式任务(Task),从而对不同数据分区的内容进行过滤。
在这种工作机制下,如果 RDD 并行度较高、或是变量的尺寸较大,那么重复的内容分发就会引入大量的网络开销与存储开销,而这些开销会大幅削弱作业的执行性能。为什么这么说呢?
要知道,Driver 端变量的分发是以 Task 为粒度的,系统中有多少个 Task,变量就需要在网络中分发多少次。更要命的是,每个 Task 接收到变量之后,都需要把它暂存到内存,以备后续过滤之用。换句话说,在同一个 Executor 内部,多个不同的 Task 多次重复地缓存了同样的内容拷贝,毫无疑问,这对宝贵的内存资源是一种巨大的浪费。
先用广播变量重写一下前面的代码实现:
import org.apache.spark.rdd.RDD
val rootPath: String = _
val file: String = s"${rootPath}/wikiOfSpark.txt"
// 读取文件内容
val lineRDD: RDD[String] = spark.sparkContext.textFile(file)
// 以行为单位做分词
val wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" "))
// 创建单词列表list
val list: List[String] = List("Apache", "Spark")
// 创建广播变量bc
val bc = sc.broadcast(list)
// 使用bc.value对RDD进行过滤
val cleanWordRDD: RDD[String] = wordRDD.filter(word => bc.value.contains(word))
// 把RDD元素转换为(Key,Value)的形式
val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, 1))
// 按照单词做分组计数
val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)
// 获取计算结果
wordCounts.collect
// Array[(String, Int)] = Array((Apache,34), (Spark,63))
我们先是使用 broadcast 函数来封装 list 变量,然后在 RDD 过滤的时候调用 bc.value 来访问 list 变量内容。
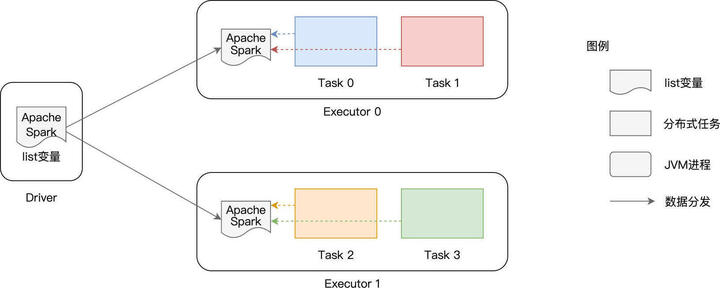
在使用广播变量之前,list 变量的分发是以 Task 为粒度的,而在使用广播变量之后,变量分发的粒度变成了以 Executors 为单位,同一个 Executor 内多个不同的 Tasks 只需访问同一份数据拷贝即可。换句话说,变量在网络中分发与存储的次数,从 RDD 的分区数量,锐减到了集群中 Executors 的个数。
在工业级系统中,Executors 个数与 RDD 并行度相比,二者之间通常会相差至少两个数量级。在这样的量级下,广播变量节省的网络与内存开销会变得非常可观,省去了这些开销,对作业的执行性能自然大有裨益。
在日常的开发工作中,当你遇到需要多个 Task 共享同一个大型变量(如列表、数组、映射等数据结构)的时候,就可以考虑使用广播变量来优化你的 Spark 作业。