Content #
所谓并行度,它实际上就是 RDD 的数据分区数量。RDD 的 partitions 属性,记录正是 RDD 的所有数据分区。因此,RDD 的并行度与其 partitions 属性相一致。开发者可以使用 repartition 算子随意调整(提升或降低)RDD 的并行度,而 coalesce 算子则只能用于降低 RDD 并行度。
为什么 repartition 会引入 Shuffle,而 coalesce 不会呢?原因在于,二者的工作原理有着本质的不同。
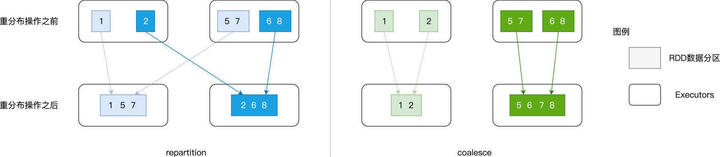
给定 RDD,如果用 repartition 来调整其并行度,不论增加还是降低,对于 RDD 中的每一条数据记录,repartition 对它们的影响都是无差别的数据分发。
具体来说,给定任意一条数据记录,repartition 的计算过程都是先哈希、再取模,得到的结果便是该条数据的目标分区索引。对于绝大多数的数据记录,目标分区往往坐落在另一个 Executor、甚至是另一个节点之上,因此 Shuffle 自然也就不可避免。
coalesce 则不然,在降低并行度的计算中,它采取的思路是把同一个 Executor 内的不同数据分区进行合并,如此一来,数据并不需要跨 Executors、跨节点进行分发,因而自然不会引入 Shuffle。