
Content #
对于任意一个 Executor 来说,Spark 会把内存分为 4 个区域,分别是 Reserved Memory、User Memory、Execution Memory 和 Storage Memory。
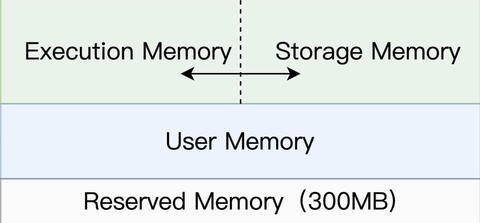
其中,Reserved Memory 固定为 300MB,不受开发者控制,它是 Spark 预留的、用来存储各种 Spark 内部对象的内存区域;User Memory 用于存储开发者自定义的数据结构,例如 RDD 算子中引用的数组、列表、映射等等。
Execution Memory 用来执行分布式任务。分布式任务的计算,主要包括数据的转换、过滤、映射、排序、聚合、归并等环节,而这些计算环节的内存消耗,统统来自于 Execution Memory。
Storage Memory 用于缓存分布式数据集,比如 RDD Cache、广播变量等等。RDD Cache 指的是 RDD 物化到内存中的副本。在一个较长的 DAG 中,如果同一个 RDD 被引用多次,那么把这个 RDD 缓存到内存中,往往会大幅提升作业的执行性能。我们在这节课的最后会介绍 RDD Cache 的具体用法。
不难发现,Execution Memory 和 Storage Memory 这两块内存区域,对于 Spark 作业的执行性能起着举足轻重的作用。因此,在所有的内存区域中, Execution Memory 和 Storage Memory 是最重要的,也是开发者最需要关注的。
在 Spark 1.6 版本之前,Execution Memory 和 Storage Memory 的空间划分是静态的,一旦空间划分完毕,不同内存区域的用途与尺寸就固定了。在 1.6 版本之后,Spark 推出了统一内存管理模式,在这种模式下,Execution Memory 和 Storage Memory 之间可以相互转化。