
Content #
我们把 Word Count 的计算逻辑,改为随机赋值、提取同一个 Key 的最大值。
import scala.util.Random._
// 把RDD元素转换为(Key,Value)的形式
val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, nextInt(100)))
// 显示定义提取最大值的聚合函数f
def f(x: Int, y: Int): Int = {
return math.max(x, y)
}
// 按照单词提取最大值
val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey(f)
reduceByKey 的计算过程如下图:
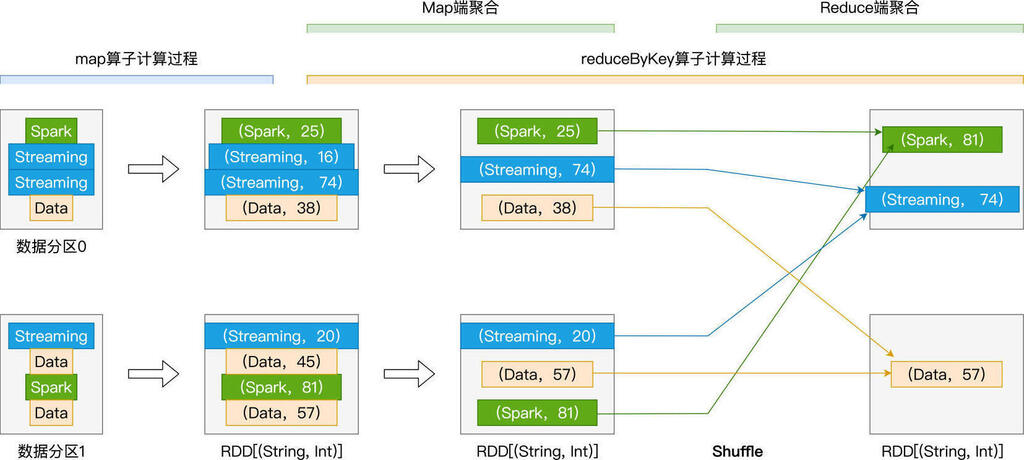
尽管 reduceByKey 也会引入 Shuffle,但相比 groupByKey 以全量原始数据记录的方式消耗磁盘与网络,reduceByKey 在落盘与分发之前,会先在 Shuffle 的 Map 阶段做初步的聚合计算。
比如,在数据分区 0 的处理中,在 Map 阶段,reduceByKey 把 Key 同为 Streaming 的两条数据记录聚合为一条,聚合逻辑就是由函数 f 定义的、取两者之间 Value 较大的数据记录,这个过程我们称之为“Map 端聚合”。相应地,数据经由网络分发之后,在 Reduce 阶段完成的计算,我们称之为“Reduce 端聚合”。
量变引起质变,在工业级的海量数据下,相比 groupByKey,reduceByKey 通过在 Map 端大幅削减需要落盘与分发的数据量,往往能将执行效率提升至少一倍。
reduceByKey 算子的局限性,在于其 Map 阶段与 Reduce 阶段的计算逻辑必须保持一致,这个计算逻辑统一由聚合函数 f 定义。当一种计算场景需要在两个阶段执行不同计算逻辑的时候,reduceByKey 就爱莫能助了。
Viewpoints #
From #
07 | RDD常用算子(二):Spark如何实现数据聚合?