
Content #
// 读取文件内容
val lineRDD: RDD[String] = _
// 以行为单位提取相邻单词
val wordPairRDD: RDD[String] = lineRDD.flatMap( line => {
// 将行转换为单词数组
val words: Array[String] = line.split(" ")
// 将单个单词数组,转换为相邻单词数组
for (i <- 0 until words.length - 1) yield words(i) + "-" + words(i+1)
})
先用 split 语句把 line 转化为单词数组,然后再用 for 循环结合 yield 语句,依次把单个的单词,转化为相邻单词词对。
注意,for 循环返回的依然是数组,也即类型为 Array[String]的词对数组。由此可见,映射函数 f 的类型是(String) => (Array[String])也就说从元素到集合。但如果我们去观察转换前后的两个 RDD,也就是 lineRDD 和 wordPairRDD,会发现它们的类型都是 RDD[String],换句话说,它们的元素类型都是 String。
map 与 mapPartitions 这两个算子在转换前后 RDD 的元素类型,与映射函数 f 的类型是一致的。但在 flatMap 这里,却出现了 RDD 元素类型与函数类型不一致的情况。
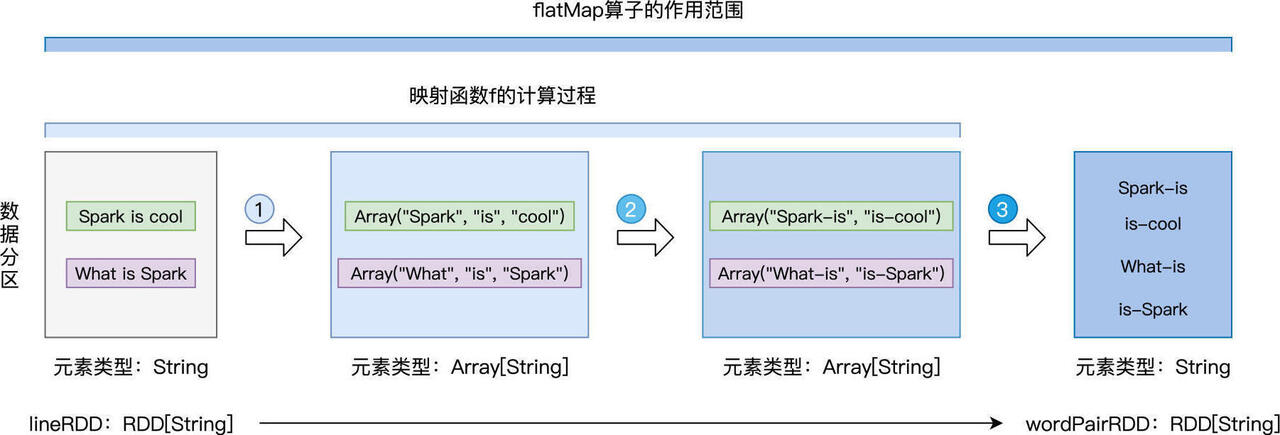
不难发现,映射函数 f 的计算过程,对应着图中的步骤 1 与步骤 2,每行文本都被转化为包含相邻词对的数组。紧接着,flatMap 去掉每个数组的“外包装”,提取出数组中类型为 String 的词对元素,然后以词对为单位,构建新的数据分区,如图中步骤 3 所示。这就是 flatMap 映射过程的第二步:去掉集合“外包装”,提取集合元素。