
Content #
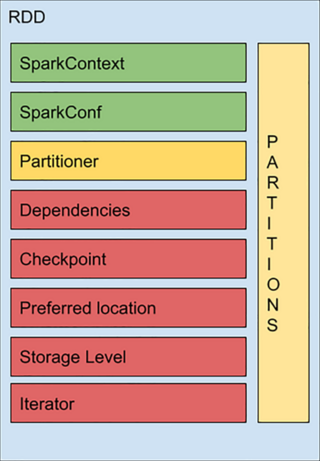
- SparkContext 所有 Spark 功能的入口,它代表了与 Spark 节点的连接,可以用来创建 RDD 对象以及在节点中的广播变量等。一个线程只有一个 SparkContext。
- SparkConf 一些参数配置信息。
- Partitioner 决定了 RDD 的分区方式,目前有两种主流的分区方式:Hash partitioner 和 Range partitioner。
- Dependencies
- Checkpoint(RDD)
- 存储级别(Storage Level)RDD
迭代函数(Iterator)和计算函数(Compute)是用来表示 RDD 怎样通过父 RDD 计算得到的。
迭代函数会首先判断缓存中是否有想要计算的 RDD,如果有就直接读取,如果没有,就查找想要计算的 RDD 是否被检查点处理过。如果有,就直接读取,如果没有,就调用计算函数向上递归,查找父 RDD 进行计算。